최근 글 목록
-
- 트위터 맞팔 논쟁
- 레니
- 2010
-
- 21세기판 골드러시 - 데이터...(1)
- 레니
- 2008
-
- 이런 스팸메일
- 레니
- 2008
-
- 구글의 새 브라우저, 크롬 (...(6)
- 레니
- 2008
-
- 다크 나이트 (The Dark Knig...(5)
- 레니
- 2008
66개의 게시물을 찾았습니다.
천문학적인 액수의 기부 활동을 하면서도 좀처럼 호감을 얻지 못하는 보기 드문 인물이 있습니다. M$의 회장 빌 게이츠가 바로 그 사람인데요, 며칠 전 빌 게이츠는 자선 사업에 집중하기 위해 은퇴를 고려 중이라는 발표를 했습니다. 물론 회장 자리가 바뀐다고 해서 M$가 얼마나 달라질지는 모르겠지만...
M$의 상징인 빌 게이츠가 많은 사람들의 원망을 받는 이유를 하나하나 헤아리기 힘들기는 하지만, 그 중에서도 OS와 오피스, 웹브라우저 등의 심각한 독점을 야기했다는 혐의와 함께, M$의 인터넷 익스플로러로 인해 웹의 표준체계가 엉망이 되어버렸다는 점이 먼저 떠오릅니다. 특히 자바스크립트(Javascript)를 사용할 때 그 폐해가 얼마나 심한지 알 수 있습니다. 자바스크립트로 제대로 된 프로그램을 작성하겠다고 마음먹었다면 익스플로러, 모질라(Mozilla), 오페라(Opera), 사파리(Safari) 등의 모든 브라우저를 위해 자바스크립트를 별도로 작성해 줘야 합니다. 특히 익스플로러에서만 작동되는 자바스크립트가 꽤 되기 때문에 각별한 주의가 필요하죠.
 앞에서 말한 자바스크립트는 (이전에도 잠깐 얘기했지만) 웹에서는 빠질 수 없는 프로그래밍 언어입니다. 여기서 뒤에 따라붙는 "스크립트"라는 단어는 자바스크립트가 "스크립트 언어"라는 점을 의미합니다. 일반적인 프로그래밍 언어와 달리 스크립트 언어는 컴퓨터가 인식할 수 있는 언어로 번역하는 과정인 "컴파일", "링크" 등의 과정이 필요없습니다. 대신 인터프리터(interpreter)라는 일종의 번역기가 컴퓨터와의 통역을 담당하게 됩니다. 이런 통역의 과정이 필요하기 때문에 스크립트 언어로 작성된 프로그램은 컴파일된 프로그램보다 실행 속도가 느리다는 단점이 있습니다. 하지만 쉽고 간편하게 작성할 수 있다는 장점 때문에 간단한 작업을 위해서 스크립트 언어는 많이 사용되곤 하죠. 웹에서는 자바스크립트를 비롯해 익스플로러에서만 실행되는 VB스크립트, 서버에서 실행되는 PHP, JSP, ASP 등의 스크립트 언어를 많이 사용합니다. 이 외에 파이썬(Python), 루비(Ruby) 등 매우 다양한 스크립트 언어가 존재합니다.
앞에서 말한 자바스크립트는 (이전에도 잠깐 얘기했지만) 웹에서는 빠질 수 없는 프로그래밍 언어입니다. 여기서 뒤에 따라붙는 "스크립트"라는 단어는 자바스크립트가 "스크립트 언어"라는 점을 의미합니다. 일반적인 프로그래밍 언어와 달리 스크립트 언어는 컴퓨터가 인식할 수 있는 언어로 번역하는 과정인 "컴파일", "링크" 등의 과정이 필요없습니다. 대신 인터프리터(interpreter)라는 일종의 번역기가 컴퓨터와의 통역을 담당하게 됩니다. 이런 통역의 과정이 필요하기 때문에 스크립트 언어로 작성된 프로그램은 컴파일된 프로그램보다 실행 속도가 느리다는 단점이 있습니다. 하지만 쉽고 간편하게 작성할 수 있다는 장점 때문에 간단한 작업을 위해서 스크립트 언어는 많이 사용되곤 하죠. 웹에서는 자바스크립트를 비롯해 익스플로러에서만 실행되는 VB스크립트, 서버에서 실행되는 PHP, JSP, ASP 등의 스크립트 언어를 많이 사용합니다. 이 외에 파이썬(Python), 루비(Ruby) 등 매우 다양한 스크립트 언어가 존재합니다.
앞에서 M$가 익스플로러에서만 작동되는 자바스크립트를 만듦으로써 자바스크립트의 표준 체계를 많이 망쳐놨다고 이야기 했는데요, 정확히 얘기하면 익스플로러에서 실행가능한 스크립트 언어는 J스크립트(JScript)라고 하는 자바스크립트와 호환되는 스크립트 언어입니다. 자바스크립트는 브렌단 아이히(Brendan Eich)라는 사람이 고안한 라이브스크립트(LiveScript)에서 기원합니다. 때는 1995년, 당시 한창 날리던 브라우저인 넷스케이프(Netscape)에서 자바 기술을 지원하기 시작했는데, 라이브스크립트 역시 자바스크립트라는 이름으로 넷스케이프에 포함되게 됩니다. 이 자바스크립트는 간편하지만 꽤 강력한 성능으로 인해 많은 인기를 끌게 되었는데요, 당시 넷스케이프의 아성에 도전하는 입장이었던 M$는 익스플로러에 자바스크립트와 호환되는 J스크립트를 장착시키게 되었죠. J스크립트에는 자바스크립트의 거의 모든 기능을 지원하는 동시에 J스크립트 만의 독자적인 문법과 기능이 추가되었는데요, 이후에 M$의 끼워팔기에 의해 익스플로러가 브라우저 세계의 대세가 되면서 자바스크립트= J스크립트 라는 등식이 자연스럽게 성립하게 되었죠.
 넷스케이프 입장에서는 참 억울하기 그지없는 시츄에이션이었을 것임이 분명합니다. 굴러온 돌이 박힌 돌을...이 문제가 아니라-_- 자바스크립트의 표준화 필요성을 느끼게 된 것이죠. 넷스케이프는 자바스크립트의 기술 명세를 ECMA(European Computer Manufacturers Association, 유럽 컴퓨터 생산자 연합...정도가 되려나요)에 제출하고, 이를 기반으로 ECMA-262라는 표준안이 작성되게 됩니다. 그래서 자바스크립트와 J스크립트를 뭉뚱그려 ECMA스크립트라는 이름으로 부르기도 하죠.
넷스케이프 입장에서는 참 억울하기 그지없는 시츄에이션이었을 것임이 분명합니다. 굴러온 돌이 박힌 돌을...이 문제가 아니라-_- 자바스크립트의 표준화 필요성을 느끼게 된 것이죠. 넷스케이프는 자바스크립트의 기술 명세를 ECMA(European Computer Manufacturers Association, 유럽 컴퓨터 생산자 연합...정도가 되려나요)에 제출하고, 이를 기반으로 ECMA-262라는 표준안이 작성되게 됩니다. 그래서 자바스크립트와 J스크립트를 뭉뚱그려 ECMA스크립트라는 이름으로 부르기도 하죠.
이러한 표준 전쟁의 결과는 어떻게 되었을까요? 아쉬울 것이 없는 M$는 ECMA-262를 만족시키면서도 J스크립트만의 독자적인 기능을 여전히 발전시켰습니다-_- 그럼 넷스케이프는? 넷스케이프 역시 자기대로 자바스크립트만의 독자적인 기능을 발전시키다가 브라우저 전쟁에서 백기를 들고 말았죠-_- 현재는 넷스케이프의 코드를 안고 출발한 모질라 파이어폭스가 자바스크립트의 유산을 계속 잇고 있습니다. 2003년에 모질라는 자바스크립트 2.0을 제안했는데요, 아직 ECMA 표준으로 반영되지는 않고 있습니다.
이런 히스토리를 볼 때, 자바스크립트 프로그램을 하나 짜려면 서로 다른 브라우저를 위해 같은 기능을 하는 코드를 중복해서 넣어줘야 하는 안타까운 현실의 책임을 빌 게이츠 한 사람에게만 돌릴 수는 없을 듯 합니다. 전쟁은 사람을 피폐하게 만든다지만, 브라우저 전쟁은 결과적으로 표준을 피폐하게 만든 셈이 되었으니까요. 하지만 다행인 것은 불여우 등 일군의 브라우저들이 표준화된 자바스크립트만을 지원하려 노력하고 있으며, ECMA 역시 진화하는 자바스크립트에 맞춰 지속적으로 새로운 판의 표준을 내놓고 있다는 것입니다. 인터넷 기업으로 진화하지 못해 위기론까지 대두되는 M$가 이번에는 어떤 행보를 보일지 궁금해지는군요.
참, 스크립트 언어의 "script"는 "각본", "대본" 등을 뜻하는 영단어에서 유래했습니다. 컴퓨터를 위한 각본을 짜는 것이 스크립트 프로그래밍인 셈인거죠. :)




 만약 처음 보는 어떤 사람이 프로그래머인지 아닌지 알고 싶다면(이런 경우가 얼마나 될지는 모르겠습니다만) 한 가지 좋은 방법을 알려드리겠습니다. 일단 빈 종이에 원통을 하나 그립니다. 그리고 이 원통을 보고 가장 먼저 떠오르는 이미지가 무엇인지 물어보는 거죠. 물론 돌아오는 대답은 블럭부터 시작해서 필통, 드럼통, 커피캔, 물컵, 스탠드, 의자 등 매우 다양할 것임이 틀림없습니다. 하지만 만약 상대방이 프로그래머라면 100이면 99 "데이터베이스"라고 대답하지 않을까 합니다;;; 데이터베이스를 상징하는 기호가 바로 이 원통이기도 하지만, 프로그래밍에 있어 데이터베이스는 어디에도 빠지지 않는 매우 중요한 존재이기 때문입니다.
만약 처음 보는 어떤 사람이 프로그래머인지 아닌지 알고 싶다면(이런 경우가 얼마나 될지는 모르겠습니다만) 한 가지 좋은 방법을 알려드리겠습니다. 일단 빈 종이에 원통을 하나 그립니다. 그리고 이 원통을 보고 가장 먼저 떠오르는 이미지가 무엇인지 물어보는 거죠. 물론 돌아오는 대답은 블럭부터 시작해서 필통, 드럼통, 커피캔, 물컵, 스탠드, 의자 등 매우 다양할 것임이 틀림없습니다. 하지만 만약 상대방이 프로그래머라면 100이면 99 "데이터베이스"라고 대답하지 않을까 합니다;;; 데이터베이스를 상징하는 기호가 바로 이 원통이기도 하지만, 프로그래밍에 있어 데이터베이스는 어디에도 빠지지 않는 매우 중요한 존재이기 때문입니다.
데이터베이스(Database)는 말 그대로 데이터를 저장하고 분류하고 찾기 쉽게 만들어 놓은 것입니다. 데이터는 단지 많다고 해서 가치있는 것이 아니라 분류/정리가 잘 되어 있어야 진정 가치를 발할 수 있기 때문에, 데이터베이스는 그런 의미에서 매우 중요한 역할을 담당하는 경우가 많죠.
책이나 음반 등을 많이 가지고 계신 분들은 이 말에 100% 공감하시리라 생각합니다. 책을 몇 천권 소유하고 있지만 방 한 구석에 쌓아놓고 보관하는 A모씨의 예를 들어봅시다. 일단 방문객에게 허접하다는 인상을 주는 건 차지하고서라도, 어떤 책이 필요해져서 찾으려고 할 때 엄청난 시간과 노력이 들기 마련입니다. 먼지를 뒤집어 쓰면서 책을 찾아봤지만 결국 찾는데 실패하게 된다면, A모씨가 소장하고 있는 몇 천권의 책들은 아무런 가치를 만들어 줄 수 없습니다. 반면 몇 백권 밖에 안되지만 책꽂이에 제목 순으로 배열된 B모씨의 책들은 가치있게 사용되는 경우가 더 많겠죠.
그래서인지 데이터베이스는 도서관과 유사한 점이 많습니다. 기본적으로 데이터베이스는 정보를 저장하고 보관하는 역할을 하는데, 도서관의 역할이 바로 그것이죠. 규모가 좀 되는 도서관에서 방 별로 분류하여 책을 보관합니다. 소설, 인문서, 논문, 간행물, 외국서적 등 몇 가지 범주로 책을 분류하여 다른 방에 넣는데, 데이터베이스에서는 테이블(Table)이 이 역할을 합니다. 테이블은 보관하고자 하는 데이터의 가장 기본적인 집합으로서, 테이블을 정의하는 사람이 데이터의 종류에 맞게 열(컬럼, Column)을 지정해 주고 테이블을 생성하면 데이터를 저장할 준비는 완료됩니다. 예를 들어 회원 정보를 저장하기 위해 데이터베이스를 사용한다고 하면,아이디/비밀번호/이름 등(주민등록번호 등은 받지 않아도 됩니다.ㅎㅎ)을 컬럼으로 잡고 테이블을 생성합니다. 그러면 테이블이라는 이름 그대로 하나의 표처럼 데이터를 저장할 구조체가 만들어지게 되죠.
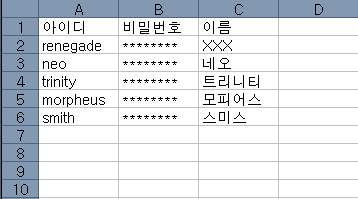
테이블은 표와 같습니다. 아이디, 비밀번호 등을 구분한 열이 있다면, 하나의 완전한 데이터로 저장되는 renegade/********/XXX 를 행(로우, row)이라고 합니다. 새로운 데이터는 하나의 새로운 행이 되어 테이블에 추가됩니다. 그리고 만약 다른 종류의 데이터를 저장할 필요성이 생기면 새로운 테이블을 만들고 데이터를 넣으면 되는 것이죠.
테이블에는 저장한 순서대로 데이터가 쌓이게 됩니다. 이렇게 되면 저장할 때에는 별 문제가 없겠지만 특정한 데이터를 찾고자 할 때 불편함이 따르게 됩니다. 10만 행의 데이터가 들어있는 위의 회원 정보 테이블에서 oracle(!!!)이라는 아이디를 가진 회원의 정보를 찾는다고 가정합시다. 그런데 운나쁘게도 oracle의 회원 정보는 99999번째로 저장되었습니다. 이런 경우에는 아이디가 oracle인지 확인하는 작업을 1번부터 시작해서 99999번 반복해야 합니다. 참 불편하기 짝이 없는 시추에이션인 것이죠.
보통 도서관에서 책을 찾을 때 이러한 불편을 덜기 위해 색인을 사용합니다. 색인은 가나다 순으로 분류되어 있고 특정 책에는 코드값이 있어서 이 코드값을 통해 쉽게 책의 위치를 알아낼 수 있습니다. 데이터베이스에도 역시 색인(인덱스, Index)이 있습니다. 테이블의 특정 컬럼에 인덱스를 걸어주면 쉽게 데이터가 있는 행의 위치를 파악할 수 있죠. 회원 정보 테이블의 아이디 컬럼에 인덱스를 걸어준다면, 테이블에 데이터가 저장될 때마다 아이디와 데이터가 들어있는 행의 위치를 인덱스에 별도로 기록합니다. 그래서 나중에 oracle이라는 아이디를 통해 데이터를 검색하고자 할 때, 99999번째 위치라는 사실을 손쉽게 찾을 수 있는 것이죠.
이외에도 데이터베이스에는 데이터를 저장하고 찾기 쉽게 하기 위한 기능들이 많이 있습니다. 같은 아이디를 중복해서 저장하고 싶지 않다면 아이디 컬럼에 대해 유일성 제약조건(Unique Constraint)을 걸어주면 됩니다. 데이터가 하나 들어갈때마다 1, 2, 3, 4 같이 자동으로 하나씩 늘어나는 번호를 데이터에 붙여주고 싶다면 시퀀스 제네레이터(Sequence Generator)를 사용하면 되지요. 다른 테이블에서 회원정보 테이블의 아이디 값을 반드시 참조하게 하고 싶다면 아이디 컬럼을 외부키(Foreign Key)로 잡아주면 됩니다.
이렇게 데이터를 테이블로 저장하고, 인덱스를 걸어주고, 다른 테이블의 값을 참조하게 하게 하면 각 테이블은 서로간의 관계를 맺게 됩니다. 이런 관계를 도면화시킨 것을 ERD(Entity Relationship Diagram)이라 부르며, ERD는 시스템의 구조를 설명해 주는 중요한 문서 중 하나로 작성됩니다.
앞에서 프로그래머를 분간하는 방법을 말씀 드렸는데요, 그 방법을 사용할 때 주의할 점이 하나 있습니다. 데이터베이스는 프로그래밍에서 빼놓을 수 없는 중요한 부분이기는 하지만, 저를 포함한 많은 프로그래머들은 데이터베이스를 다루는 것을 별로 좋아하지 않습니다. 순수하게 데이터만을 만지작거리는 건 아무래도 지루하고 재미없는 일이기 때문이죠. 원통을 그려 보였을 때 상대방이 프로그래머라면 알러지 반응을 보일 수도 있으니 주의하세요. :)
얼마 전에 N모사의 검색전략팀장이 회사로 찾아와 세미나를 한 적이 있었습니다. 많은 사람들이 몰려들어 성황을 이루었지만, "소문난 잔치에 먹을 거 없다"는 말처럼 그다지 새로운 이야기는 (기업 비밀이라 비공개였는지 몰라도) 없었죠. N모사의 역사, 사업 분야, 현황 등 다양한 얘기들을 했습니다만 그 중에 최근에 서비스 오픈한 오픈API(OpenAPI)에 대해 상당히 많은 시간을 들였습니다. 개인적으로 어쩌면 대형 포탈과 가장 어울리지 않는 것이 API 서비스라고 생각하는데, 오픈API에 기대를 많이 하는 모습을 보니 의외란 생각이 들더군요.
오라일리(Tim O'Reilly)가 제시한 웹2.0이라는 애매모호한 개념이 전세계를 떠돌면서 본래는 프로그래머들이나 사용하던 "API"라는 단어가 많이 쓰이게 되었습니다. 그러나 태깅(tagging), 블로그, 위키(wiki) 등 분명하게 실체가 존재하는 단어들에 비해, 본래부터 기술적인 단어인 "API"는 상대적으로 널리 알려지지 않았다고 보입니다. 웹2.0이 처음 얘기되던 시기에 폭발적인 인기를 얻었던 웹2.0 밈맵(meme map)에서도 API는 보이지 않는군요. :)
API는 Application Program Interface, 또는 Application Programming Interface의 약자로, "응용 프로그램(프로그래밍) 인터페이스" 정도로 번역 가능합니다. 한글로 풀어놔도 별반 쉬운 말이 아니군요-_-;; 여기에 "인터페이스"라는 단어가 나오는데, 일반적으로 인터페이스는 다른 주체와의 소통을 위해 접근할 수 있는 통로, 또는 매개체를 의미하죠.(위키백과(Wikipedia)의 예가 아주 적절하네요.) 컴퓨터 세계에서 인터페이스는 사용자/프로그래머와 컴퓨팅 시스템 사이에서 의사소통을 매개하는 존재을 의미합니다.
마이크로소프트의 윈도를 윈도3.0 시절부터 사용하시던 사용자라면 아마 GUI라는 단어를 들어보셨을 것입니다. 당시에는 도스(DOS)라는 문자형 운영체제가 주로 사용되었었는데 DOS에서는 일일히 키보드로 명령어를 쳐야지만 동작을 수행할 수 있었죠. 예를 들면 특정 디렉토리(폴더) 안에 어떤 파일들이 있는지 보고 싶다면 아래와 같이 dir/a라는 명령어를 직접 쳐야만 했습니다. 컴퓨터에게 명령을 실행시키기 위해서 열심히 키보드를 때려야만 했던 시절이었죠. (그래서인지 도스 시절부터 컴퓨터를 사용했던 사용자들은 영타가 꽤 빠릅니다.ㅎㅎ)

MS는 매킨토시의 OS인 맥OS(MacOS)의 영향을 받아 윈도의 초기 버전을 출시하게 됩니다. 이 당시 도스와 윈도를 구별하기 위해 GUI라는 말을 일반화시켰죠. 여기서 GUI는 Graphic User Interface, 즉 그래픽 유저 인터페이스의 약자입니다. 윈도를 비롯한 그래픽을 통한 인터페이스를 사용하는 OS들은 마우스만으로도 거의 모든 작업을 수행할 수 있습니다. 폴더의 파일들을 보기 위해 마우스 클릭만 하면 되는 것이죠. 컴퓨터에게 말을 걸기가 더 쉬워진 것이죠. 이렇게 컴퓨터와의 대화를 하기 위해 필요한 매개가 되는 것을 인터페이스라고 합니다.
유저 인터페이스 같이 API 역시 컴퓨터와 의사소통하기 위한 매개입니다. 다만 소통을 위한 언어가 프로그래밍 언어라는 점이 다르죠. 아무리 실력이 뛰어난 프로그래머라고 할지라도 컴퓨터와 관련된 모든 일들을 프로그래밍할 수 없습니다. 예를 들면, 특정 문서를 프린트하는 프로그램을 만들기 위해 문서를 열고 화면에 문서 내용을 보여주고 프린터로 문서 내용을 보내서 프린트하는 프로그램을 전부 만들기에는 아무래도 힘이 들지요. 일반적으로 이런 경우에는 원하는 기능을 해 주는 API를 사용합니다. 문서를 열고 내용을 읽어들이는 API, 프린터를 제어하는 API 등을 사용하여 프로그래밍을 하기 때문에 해야 할 일이 많이 줄어들 수 있는 것이죠. 물론 사용하는 API는 프로그래밍하고자 하는 언어(C나 자바 등)로 되어 있어야 하겠죠.
아까 얘기한 N모사의 오픈API를 사용해서 요청을 보내면 N모사의 검색 결과를 RSS로 얻을 수 있습니다. RSS를 통해 전달되는 결과에는 순수한 데이터만 들어있기 때문에, 이 데이터를 가공하여 자신의 홈페이지나 블로그 등에 편집하여 사용할 수 있습니다. N모사의 사이트에 직접 가서 검색 결과를 얻는 것이 아니라 자신의 페이지에 검색 결과를 나타낼 수 있다는 점에서 기존의 방식과 차이가 있는 것이죠.

사용자의 구미에 맞게 데이터를 얻고 편집할 수 있는 API도 하나의 대세가 된 느낌입니다. 이미 알만한 인터넷 서비스 업체들은 API 서비스를 오픈하거나 준비하고 있습니다. 구글은 이미 오래 전부터 API 서비스를 제공하고 있었고, 플리커, 델리셔스, 국내에서도 D모사의 블로그 API, E모사의 블로깅 API 등 API 서비스를 제공하지 않으면 시대에 뒤쳐지는 느낌까지 드는 게 사실이죠. :)
이러한 API는 다양한 정보들을 확산시키는 긍정적인 역할을 하리라 기대하고 있습니다. 정보의 공유과 확산의 정반대 위치에 있는 포털들마저 API 서비스를 제공하는 모습을 보면, 웹2.0이 비록 정체 불명의 개념일지라도 분명한 가치를 지닌 패러다임이라는 생각이 들기도 하니깐요.
 지금의 저는 어떠한 종교도 가지고 있지 않지만, 소시적 C 종교를 열심히 믿던 시절이 있었습니다. C 종교의 경전에는 "바벨탑" 이야기가 나오는데요, 이 바벨탑은 "신의 경지에 도전하려는 인간의 무모함"에 대한 비유로 지금도 많이 언급되곤 하죠. 이 바벨탑이 세워지던 시절에는 세상에 단 하나의 언어만이 존재했기 때문에 모든 이들이 자유롭게 소통할 수가 있었습니다. 그러나 C 종교의 유일신은 인간들의 도전행위를 용납하지 않는 성격이어서, 탑을 쌓는 사람들의 언어를 흩어놓는 능력을 발휘합니다. 말이 통하지 않게 되자 사람들은 사방으로 흩어지게 되었고, 결국 유일신은 자신의 목적을 간단하게 달성할 수 있게 되었죠.
지금의 저는 어떠한 종교도 가지고 있지 않지만, 소시적 C 종교를 열심히 믿던 시절이 있었습니다. C 종교의 경전에는 "바벨탑" 이야기가 나오는데요, 이 바벨탑은 "신의 경지에 도전하려는 인간의 무모함"에 대한 비유로 지금도 많이 언급되곤 하죠. 이 바벨탑이 세워지던 시절에는 세상에 단 하나의 언어만이 존재했기 때문에 모든 이들이 자유롭게 소통할 수가 있었습니다. 그러나 C 종교의 유일신은 인간들의 도전행위를 용납하지 않는 성격이어서, 탑을 쌓는 사람들의 언어를 흩어놓는 능력을 발휘합니다. 말이 통하지 않게 되자 사람들은 사방으로 흩어지게 되었고, 결국 유일신은 자신의 목적을 간단하게 달성할 수 있게 되었죠.
사실 언어라는 것이 이렇게 누군가가 정해 주는 것은 아니겠죠. 지역마다 독자적으로 발전한 역사적인 산물이 언어이기 때문에 세상에는 이토록 다양한 언어들이 존재하는 것일 겁니다. 이러한 언어의 다양성은 각 지방의 고유한 문화를 드러내기도 하지만, 지역간의 커뮤니케이션을 방해하는 가장 큰 요인이 되기도 합니다. 그리고 이런 사정은 가상 공간인 웹에서도 마찬가지입니다.
 컴퓨터는 바이트(byte) 단위로 문자를 구분합니다. 한 바이트는 8비트(bit)로 구성되며 0부터 255까지의 숫자를 표현 가능하죠. 컴퓨터가 처음 발명되었을 때 이를 사용할 수 있는 사람은 영미권에 속해 있었기 때문에 다양한 언어로 인한 문제 때문에 골치 썩일 일은 없었습니다. 0부터 9까지의 숫자 10개와 대/소문자 알파벳 52개, 그리고 몇 가지의 특수 문자들만 표현하면 되었죠. 이를 표현하기 위해 각 문자를 0에서 255사이의 수로 표현하는 방법을 사용했습니다. 예를 들어 알파벳 A는 65번, a는 97번, -(대시)는 45번, 공백(스페이스)는 32번 등으로 말이죠. 이렇게 각 문자들에 수를 할당하고 나면 0부터 127번까지 사용하게 됩니다. 이런 규칙이 바로 ASCII(American Standard Code for Information Interchange, 아스키) 코드죠. 아스키 코드는 오래 전부터 영문을 표기하는 표준으로 자리잡아 왔으며 이후에 0부터 255까지를 사용하는 확장 아스키 코드가 나온 후 현재까지 사용되고 있습니다.
컴퓨터는 바이트(byte) 단위로 문자를 구분합니다. 한 바이트는 8비트(bit)로 구성되며 0부터 255까지의 숫자를 표현 가능하죠. 컴퓨터가 처음 발명되었을 때 이를 사용할 수 있는 사람은 영미권에 속해 있었기 때문에 다양한 언어로 인한 문제 때문에 골치 썩일 일은 없었습니다. 0부터 9까지의 숫자 10개와 대/소문자 알파벳 52개, 그리고 몇 가지의 특수 문자들만 표현하면 되었죠. 이를 표현하기 위해 각 문자를 0에서 255사이의 수로 표현하는 방법을 사용했습니다. 예를 들어 알파벳 A는 65번, a는 97번, -(대시)는 45번, 공백(스페이스)는 32번 등으로 말이죠. 이렇게 각 문자들에 수를 할당하고 나면 0부터 127번까지 사용하게 됩니다. 이런 규칙이 바로 ASCII(American Standard Code for Information Interchange, 아스키) 코드죠. 아스키 코드는 오래 전부터 영문을 표기하는 표준으로 자리잡아 왔으며 이후에 0부터 255까지를 사용하는 확장 아스키 코드가 나온 후 현재까지 사용되고 있습니다.
영문만을 컴퓨터에서 사용하던 시절에는 아스키 코드만으로 충분했었습니다. 그러나 곧 세계 각국에서 컴퓨터를 사용하게 되었고 사용자들은 자신이 사용하는 언어를 표현할 수 있어야 했죠. 이 중 알파벳처럼 적은 수의 문자를 사용하고 있기 때문에 아스키 코드처럼 자신의 언어를 코드화할 수 있는 나라들도 있었지만, 한국이나 일본, 중국 등의 아시아권 국가들은 255 이상의 수를 필요로 했었죠. 그래서 한국어 등의 언어들은 2바이트를 사용하여 자신의 언어를 표현하기 시작합니다. 1바이트로 표현할 수 있는 수는 0에서 255이지만, 2바이트로는 65535까지 표현할 수가 있기 때문에 보다 많은 문자들을 코드값으로 나타낼 수 있게 되었죠. 한국의 경우 이 과정에서 표준을 주관하는 곳이 없었기 때문에 조합형, 완성형, 확장 완성형 등의 여러 코드 체계들이 난립하게 되었습니다. 흔히 EUC-KR, KSC-5601, ISO-8859-1 등으로 불리는 것들이 이러한 코드 체계의 이름으로서 이를 "캐릭터셋"이라고 부릅니다. (정확히 얘기하면 EUC-KR은 "인코딩"으로 불러야 합니다) 한국에서는 완성형이라고 불리던 코드 체계를 결국 국가 표준으로 삼게 되었고, 유니코드에서도 역시 완성형 한글을 기본으로 하게 됩니다.
 여기서 유니코드라는 말은 여러 곳에서 많이 들어보셨을 것입니다. 유니코드란 어떻게 보면 현대의 바벨탑 같은 것이라고 할 수 있습니다. 만약 일본어로 제작된 문서를 한국어 운영체제로 된 컴퓨터에서 읽는다고 가정해 봅시다. 그냥 문서를 한국어 문서 읽듯이 문서편집기로 연다면 깨진 글자들 밖에 볼 수 없을 것입니다. 문서를 제대로 읽기 위해서 가장 먼저 이 문서가 어떤 캐릭터셋으로 표현되었는지를 알아야 하고, 그 다음으로 그 캐릭터셋의 표현 규칙을 알고 있어야만 일본어를 제대로 표시할 수 있겠죠. 바꿔말하면 세상에 존재하는 수많은 나라에서 사용하는 캐릭터셋의 규칙을 모두 가지고 있어야만 어떤 문서라도 읽을 수 있다는 말이 됩니다. 이것은 참 불편하고 비효율적인 일이 아닐 수 없겠죠. 그래서 전세계의 문자를 공통의 문자 코드로 관리하려는 유니코드 프로젝트가 시작됩니다. 유니코드는 3바이트 영역까지 사용하여 전세계의 문자를 표현하려 합니다. 따라서 유니코드 형태로 표현하면 하나의 표현 규칙만 알고 있어도 어떠한 문자도 읽을 수 있게 되겠죠.
여기서 유니코드라는 말은 여러 곳에서 많이 들어보셨을 것입니다. 유니코드란 어떻게 보면 현대의 바벨탑 같은 것이라고 할 수 있습니다. 만약 일본어로 제작된 문서를 한국어 운영체제로 된 컴퓨터에서 읽는다고 가정해 봅시다. 그냥 문서를 한국어 문서 읽듯이 문서편집기로 연다면 깨진 글자들 밖에 볼 수 없을 것입니다. 문서를 제대로 읽기 위해서 가장 먼저 이 문서가 어떤 캐릭터셋으로 표현되었는지를 알아야 하고, 그 다음으로 그 캐릭터셋의 표현 규칙을 알고 있어야만 일본어를 제대로 표시할 수 있겠죠. 바꿔말하면 세상에 존재하는 수많은 나라에서 사용하는 캐릭터셋의 규칙을 모두 가지고 있어야만 어떤 문서라도 읽을 수 있다는 말이 됩니다. 이것은 참 불편하고 비효율적인 일이 아닐 수 없겠죠. 그래서 전세계의 문자를 공통의 문자 코드로 관리하려는 유니코드 프로젝트가 시작됩니다. 유니코드는 3바이트 영역까지 사용하여 전세계의 문자를 표현하려 합니다. 따라서 유니코드 형태로 표현하면 하나의 표현 규칙만 알고 있어도 어떠한 문자도 읽을 수 있게 되겠죠.
현재 한국의 많은 웹페이지들이 KSC-5601 캐릭터셋을 기반으로 한 EUC-KR 인코딩을 사용하고 있습니다. EUC-KR은 유니코드가 아니기 때문에 한국어와 일부 한자를 제외한 다른 언어를 표현하기 어렵습니다. 그래서 UTF-8 인코딩을 통한 유니코드를 사용하려는 움직임이 활발하게 일어나고 있으며, 많은 페이지들이 UTF-8을 사용하여 제작되고 있죠. 하지만 EUC-KR만을 처리하던 페이지에서는 유니코드를 인식하지 못하기 때문에 깨진 글자로 나타나는 등 아직은 혼란스러운 양상입니다. 따라서 현재로는 모든 캐릭터셋을 인식할 수 있도록 페이지를 제작하는 것밖에는 방법이 없습니다. 물론 그만큼 시간과 노력이 더 들어가겠지만요. :)
 1월 말 마이크로소프트에서 작은 뉴스 하나를 발표했습니다. 관심있는 사람이 아니면 쉽게 지나칠만한 기사였지만, 어떻게든 관련이 있는 웹개발자들에게는 대단히 나쁜 소식이었죠. 바로 액티브엑스(ActiveX) 동작과 관련해 인터넷 익스플로러(IE)의 설계를 변경한다는 발표입니다.
1월 말 마이크로소프트에서 작은 뉴스 하나를 발표했습니다. 관심있는 사람이 아니면 쉽게 지나칠만한 기사였지만, 어떻게든 관련이 있는 웹개발자들에게는 대단히 나쁜 소식이었죠. 바로 액티브엑스(ActiveX) 동작과 관련해 인터넷 익스플로러(IE)의 설계를 변경한다는 발표입니다.
인터넷 업계의 공룡기업답게 마이크로소프트는 여러 다른 회사들과 이런저런 소송에 얽혀 있습니다. 이 중 ActiveX라는 기술 등을 HTML 파일에서 사용하는 방식에 대해 캘리포니아 주립대와 이올라스 테크놀러지(Eolas Technologies)와의 특허 분쟁을 진행하는 중이었는데, 이 과정에서 특허 침해 소지를 없애기 위해 자사의 웹브라우저인 인터넷 익스플로러에서 ActiveX 등의 동작법을 변경하게 된 것이죠.
아마 페이지를 열면 자동으로 음악이 재생되거나 프로그램이 실행되는 경우를 보셨을 것입니다. 이것은 브라우저의 자체적인 기능이 아니라 미디어 플레이어 같은 외부 프로그램("컨트롤"이라 부릅니다)을 통해 실행시키는 것인데요, HTML에서 [OBJECT], [embed], [APPLET] 등의 태그를 사용해 컨트롤을 불러오게 되죠. 위에서 얘기한 특허는 HTML에서 이 태그들을 사용해 사용자의 입력 없이 자동으로 컨트롤을 활성화시키는 것에 대한 내용입니다. 따라서 변경된 인터넷 익스플로러에서는 반드시(!) 사용자의 입력을 통해서만 이러한 컨트롤들이 동작하게 됩니다. 만약 음악을 자동재생시켜 놓으면 이제까진 정지 버튼만 눌러주면 음악을 멈출 수 있었지만, 앞으로는 미디어 플레이어 컨트롤을 한 번 클릭해서 활성화 시킨 다음 정지를 누를 수 있게 된 것이죠.
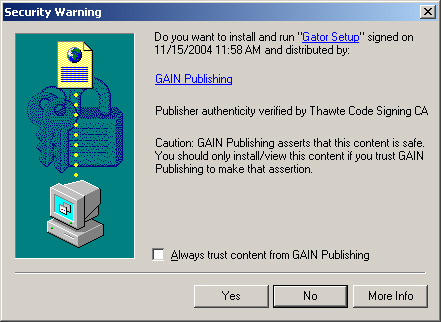
사실 자동재생된 음악을 멈추려면 클릭 한 번을 더 해줘야 된다...정도의 문제라면 그다지 큰 이슈가 되진 않았을 겁니다. 하지만 인터넷 익스플로러에서만 사용할 수 있는 ActiveX 컨트롤이 자동으로 동작하지 않는다는 점이 문제가 되고 있습니다.
여기서 ActiveX란 COM(Component Object Model)이라는 기술을 기반으로 하는 마이크로소프트가 제안한 컴포넌트 기술입니다. 워드(Word) 같은 어플리케이션 프로그램은 사용자의 PC에서 실행시켜 사용하는 것밖에 방법이 없지만, ActiveX로 개발한 프로그램은 HTML 문서 등에서 실행할 수 있으며 다른 어플리케이션에 쉽게 붙일 수도 있습니다. ActiveX 프로그램을 통해 문서편집기나 그림판, 네트워크 어플리케이션 등의 강력한 프로그램을 웹문서에서 사용할 수 있게 된 것이죠. 은행 웹사이트 같은 데를 접속하면 가장 먼저 보안 프로그램을 체크하고 없으면 새로 설치하는데, 이런 프로그램들도 대부분 ActiveX로 개발되어 있습니다.
 하지만 ActiveX가 마이크로소프트라는 특정 회사에 속한 기술이기 때문에 마이크로소프트의 플랫폼에서만 동작한다는 한계가 있습니다. 리눅스나 매킨토시 같은 운영체제에서 사용할 수 없음은 물론이고, 모질라 파이어폭스나 오페라 등의 브라우저에서도 ActiveX를 사용할 수 없습니다. 파이어폭스 사용자들은 ActiveX 형태의 보안 모듈을 설치할 수 없기 때문에 인터넷 뱅킹을 하기 힘듭니다. 대부분의 금융기관 사이트에서 인터넷 익스플로러를 기준으로 웹사이트를 구축했기 때문이죠.
하지만 ActiveX가 마이크로소프트라는 특정 회사에 속한 기술이기 때문에 마이크로소프트의 플랫폼에서만 동작한다는 한계가 있습니다. 리눅스나 매킨토시 같은 운영체제에서 사용할 수 없음은 물론이고, 모질라 파이어폭스나 오페라 등의 브라우저에서도 ActiveX를 사용할 수 없습니다. 파이어폭스 사용자들은 ActiveX 형태의 보안 모듈을 설치할 수 없기 때문에 인터넷 뱅킹을 하기 힘듭니다. 대부분의 금융기관 사이트에서 인터넷 익스플로러를 기준으로 웹사이트를 구축했기 때문이죠.
게다가 ActiveX는 심각한 보안문제를 일으키는 원인이 되기도 합니다. ActiveX 자체가 지닌 보안 취약성도 심심치 않게 발견되고 있으며, 바이러스나 트로이목마 프로그램처럼 사용자의 PC에 악영향을 줄 수 있는 프로그램이 ActiveX 형태로 배포되는 경우도 많습니다. 윈도 어플리케이션 형태의 프로그램과 달리 ActiveX 프로그램은 한 번의 클릭만으로 설치되어 버리기 때문에, 악의적인 코드가 침투할 가능성이 더 높습니다. 따라서 ActiveX를 설치할 때에는 신중하게 "예" 버튼을 눌러줘야겠죠.
여튼 ActiveX의 존재 때문에 일이 이렇게 커진 셈이 된 것인데요, 그래도 (마이크로소프트의 입장에서만 다행스럽게도) 이 문제를 피해갈 수 있는 방법이 있습니다. [OBJECT], [embed], [APPLET] 등의 태그를 HTML에 직접 쓰지 않고 자바스크립트 등의 스크립트에서 써 주게 되면 특허를 피해갈 수 있게 된 것이죠. 것이죠. 결국 마이크로소프트에서는 특허료를 지불하고 기술을 사용하기 보다는, 돈 적게 들이고 품을 적게 팔 수 있는 방법으로 인터넷 익스플로러를 패치하기로 결정하게 된 것입니다.
결국 마이크로소프트의 이 결정으로 인해 웹개발자들은 수많은 페이지에서 사용되는 ActiveX 컨트롤들을 위해 코드를 수정해주는 작업을 해 줘야 하게 되었습니다. 마이크로소프트는 "우리가 일일히 다 수정해 줄 수도 없는 노릇이고... 그렇다고 특허 사용료를 내긴 돈 아깝잖냐. 꽁수를 알려줄테니 조금 미안하긴 하지만 니네가 알아서 해라~"라고 배를 째는 상황이니. 인터넷 익스플로러를 비롯해 마이크로소프트에 대한 의존도가 지나치게 높은 한국에선 이래저래 피해를 많이 볼 수밖에 없는 것이죠. 특정 소프트웨어에 의한 독점이 가져다주는 피해를 엿볼 수 있는 한 단면이 아닌가 합니다.
사실 블로그를 시작하고 트랙백이라는 개념을 이해했을때,
이런 게 당연히 있으리라고 생각은 했었지만...
여러 블로그에서 당했다는 얘기도 듣긴 했었지만...
아무리 그래도 트랙백으로 스팸을 날리는 건 너무하는 거 아니삼? -_-

링크 걸린 주소로 DoS 공격이라도 날려주던지 해야지 원;;;
이런 식으로 계속되면,
트랙백 키워드 필터를 추가해야 하는 게 아닌가 몰겠네요. OTL
스팸의 어원에 대해
어느 단어나 그렇겠지만, 스팸의 어원에도 여러 설이 있습니다. 그 중 가장 대중적인 설은 유명한 통조림 햄 상표인 Spam에서 왔다는 설인데요, Spam의 악명높은 광고 전단 뿌리기에서 스팸이 유래했다는 설명입니다.
한편 Wikipedia의 설명은 다음과 같습니다. 먼저 스팸이라는 단어는 영국의 유명한 코미디 프로그램인 Monty Python의 "Spam"이라는 sketch(1~10분 정도의 짧은 코미디 씬..인 것 같습니다)에서 유래했다는 설이 유력합니다. 이 코미디에 나오는 바이킹들이 "SPAM, SPAM, SPAM, SPAM"을 외치며 식당 내의 커뮤니케이션을 방해하는 장면이 있다고 합니다. 이후 여러 게시판이나 MUD 게임, 채팅 룸 등에서 "SPAM"을 연타하며-_- 커뮤니케이션을 방해하는 행위들에 스팸이라는 명칭이 붙었다가, 이메일로 날아오는 광고까지 이어지게 된 것이라고 하네요. 그리고 앞에서 얘기한 바와 비슷하게, 1937년 거의 모든 라디오 프로그램 앞에 통조림 햄 Spam의 라디오 광고를 틀었던 것로부터 유래했다는 설명도 있습니다.
뭐 어원이 무엇인들 스팸 문제 해결에는 아무런 도움이 안되겠지만요-_-;;;
2005년도 다 저물어 가는 마당에 연말 결산이 어디서나 한창이군요.
새로운 플랫폼으로서 Web 2.0이라는 개념이 각광을 받기 시작한 것도 2005년이지만,
2005년 각 분야에서 주목받은 Web 2.0 어플리케이션들을 결산하는 페이지입니다.
The Best Web 2.0 Software of 2005
관련글
블로거 지음 : 웹 2.0 - 다시 웹을 사고한다.
웹 기술과 관련한 글을 읽다보면 돔(DOM)이라는 말을 많이 접하셨을 것입니다. 이미 저도 지난 번에 Ajax에 대해 쓴 글에서 DOM을 언급한 적이 있죠. 문서객체모델(Document Object Model), 약자로 DOM이라고 부르는 객체지향적인 모델은 웹 기술에서뿐만 아니라 구조화된 데이터를 다루는 곳이라면 어느 곳에서라도 사용되고 있습니다.
HTML 같은 문서들은 태그들의 계층적인 집합으로 이루어져 있습니다. 예를 들자면 다음과 같은 문서는 HTML로 이렇게 표현이 되죠.
 |
[html] [head] [title]고양이 그림[/title] [/head] [body] [IMG id="cat_pic" src="http://imagepath" border=0] [/body] [/html]
|
이 HTML을 DOM 문서로 변환한다면 다음과 같은 DOM 객체가 만들어지게 됩니다.
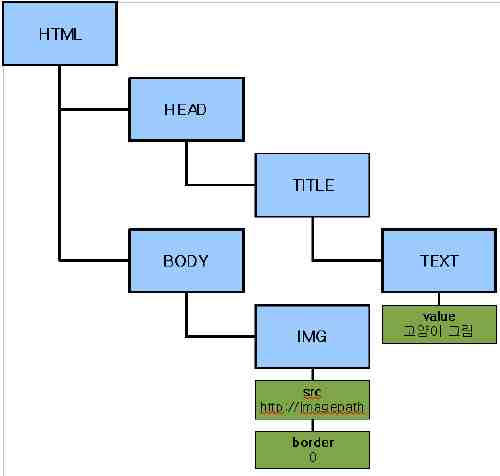
태그들은 파란색 박스 안에, 태그 안에 쓰인 속성들은 녹색 박스 안에 표시되고 있습니다. 여기서 파란 색 박스로 표시된 DOM의 기본적인 요소를 노드(Node)라고 하며, 각 노드에 딸린 녹색 박스들을 속성(Attribute)이라고 합니다. 각 노드는 다른 노드의 상/하위에 위치할 수 있으며 각 속성은 노드의 하위에 위치합니다.
이렇게 계층적인 형태를 지닌 데이터 구조를 트리(Tree)구조라 부르는데, 비단 DOM 뿐만 아니라 데이터베이스의 인덱스, 윈도의 폴더/디렉토리 등에서 트리구조를 사용합니다. 이러한 트리구조의 장점이라 하면 역시 임의의 하위 요소로 빠르게 접근이 가능하다는 것이겠죠.
문서를 DOM 객체로 변환하고 나면, 문서의 요소에 임의적으로 접근하여 내용을 수정하거나 새로운 내용을 추가하는 등의 작업이 수월해집니다. DOM 객체의 노드에 접근하기 위해 id를 많이 사용합니다. 여기서 id는 각 노드를 구별해주는 고유한 값인데, 만약 문서 안에 같은 값을 지닌 id를 지닌 노드가 두 개 이상 존재한다면 가장 첫번째 선언된 노드 이외의 노드들은 id로 접근할 수 없게 되죠.
그럼 위의 HTML 문서에서 고양이 그림을 나타내주는 [img] 노드에 접근해 봅시다. 다음은 자바스크립트를 사용하여 [img] 노드에 접근하는 코드입니다.
[script language="javascript"]
[!--
var obj = document.getElementById("cat_pic");
var result = obj.src;
//--]
[/script]
"cat_pic"라는 id를 지닌 노드를 찾아온다음, 그 노드의 src값을 얻어왔습니다. 문서의 [img] 태그의 id가 "cat_pic"였으므로, DOM에서 [IMG] 노드를 가져오게 되고, [IMG] 노드는 src 속성의 값으로 "http://imagepath"를 지니고 있으므로, 최종적으로 result에는 "http://imagepath"라는 값이 들어가게 됩니다.
이런 식으로 id를 사용하면 문서의 요소에 임의적으로 접근하여 내용을 가져올 수도 있고 변경할 수도 있습니다. 위의 예에서는 자바스크립트를 사용했지만, DOM은 기본적으로 플랫폼이나 프로그램 언어의 제한없이 사용할 수 있기 때문에, 어떤 프로그램에서든지 DOM을 이용하여 동적으로 문서의 내용을 읽고 변경할 수 있죠. 지금은 동적인 페이지를 만들기 위해서 DOM은 거의 모든 페이지에서 필수적으로 사용되는 것 중 하나라고 할 수 있습니다.
다만 DOM에서도 웹 개발에서 가장 까다로운 점 중 하나인 브라우저 사이의 호환성 문제가 존재합니다. 이러한 문제를 정리하기 위해 웹표준기구인 W3C에서 DOM 표준을 제작하였으며 역시 표준화된 프로그래밍 인터페이스(API)를 제공하고 있지만, 비표준 역시 널리 사용되고 있는 것들이 많기 때문에 까다로운 지점들이 존재합니다. 따라서 DOM을 적극적으로 사용할 때에는 다양한 브라우저 환경에서의 테스팅이 필수적이죠. 비표준 확장으로 인한 불편함은 정말이지 여러 방면에 걸쳐있는 것 같습니다^_^;;;
네트워커 원고로 작성한 포스트입니다.
과거 RSS 관련 포스트들의 짜집기라고 할 수 있죠;;;

한국에 블로그가 처음 들어왔을 때만 해도 RSS는 매우 생소한 개념이었습니다. 블로그의 메뉴 가장 하단에 생기는 "XML" 마크를 보며 이게 어디에 쓰이는 건지 의아해 하기도 했었구요. 하지만 현재 RSS는 웹에서 가장 각광받는 컨텐츠 배포 방식이 되었습니다. 개인 미디어로서 블로그의 확산과 더불어 RSS도 범용적으로 사용되게 되었고, 지금은 RSS 피드만을 전문적으로 관리해 주는 서비스도 많이 생기게 되었습니다.
RSS는 Rich Site Summary, 혹은 RDF Site Summary, 혹은 Really Simple Syndication의 약자입니다. 이 약자가 무엇이든 간에 여하튼 RSS는 어떤 웹 컨텐츠의 요약본을 제공하는 방식을 말합니다. 어떤 사이트의 컨텐츠를 보기 위해서 일반적으로 웹브라우저를 열고 특정 URL을 주소창에 입력하여 그 사이트가 브라우저에 뜬 후 내용을 읽곤 합니다. 하지만 RSS를 이용하면 이런 식으로 돌아다니면서 정보를 찾는 것이 아니라 정보를 자신에게 가져와 모아서 볼 수 있게 됩니다.
RSS가 널리 사용되는 이유 중 가장 큰 것은 컨텐츠 수용자에게 있어 매우 편리한 컨텐츠 수집 방법이기 때문입니다. RSS를 통해 거의 실시간으로 새로운 컨텐츠의 업데이트를 알려주고, 컨텐츠가 아무리 많다 하더라도 이를 범주화시키고 원하는 방식으로 정렬해서 보여줄 수 있습니다. 만약 특정 블로그나 사이트의 컨텐츠에만 관심있는 사람이라면 일일히 브라우저에서 URL을 치고 들어가는 것보다 한 번에 모든 컨텐츠를 모아서 볼 수 있는 RSS 리더를 선호할 것이라는 점은 분명하죠.
동시에 컨텐츠 제공자에게 있어서도 RSS는 보다 다양한 방식으로 컨텐츠를 제공할 수 있는 수단이 됩니다. 자신이 제공하는 컨텐츠를 재편집해서 새로운 컨텐츠의 집합을 만들 수도 있고, 다른 RSS 제공자와 연합하여 또 다른 의미의 컨텐츠 집합을 만들 수 있습니다. 즉, 저작권 문제만 조율한다면 여러 곳에서 생산하는 컨텐츠들을 재가공할 수가 있게 되는데, 이는 RSS XML이라는 표준적인 컨텐츠 배포 형식이 존재하기 때문에 가능한 것이죠.
RSS에서 사이트의 정보를 나타내기 위해 XML을 사용합니다. XML(eXtensible Markup Language)은 간단하게 말하면 데이터 교환을 위한 표준으로, 특히 계층형 데이터를 쉽게 표현할 수 있다는 장점이 있습니다. 예를 들면 다음은 블로그의 카테고리 정보를 XML로 표현한 것입니다.
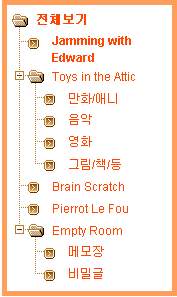
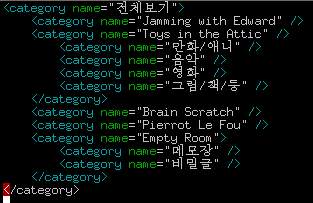
XML은 HTML과 마찬가지로 태그 기반의 마크업 언어(markup language)이기 때문에, 태그를 정의하기에 따라 다른 용도로 사용할 수 있습니다. 프로그램의 기본적인 설정을 기록해둔 설정 파일로도 사용할 수 있고, 요즘 추세에 따르면 심지어 XML로 프로그래밍을 하기도 합니다. 그러나 가장 많이 사용되는 것은 데이터 교환의 용도로 쓰이는 것인데, 대표적인 예를 들면 웹에서 기사를 출판하는 언론의 경우, 기사를 XML 형식에 맞춰 보내면 자동으로 HTML 페이지를 만들어주기도 합니다. 표준에 맞게 XML만 만들면 다른 언론사의 기사라도 쉽게 받아 쓸 수 있게 되는 셈이죠.
물론 RSS에도 별도의 XML 표준이 있습니다. 현재는 많은 곳에서 RSS 2.0을 기준으로 XML을 생성하고 있는데, RSS 2.0은 RSS 1.0과 달리 웹표준기구인 W3C의 표준에 호환가능하다는 장점이 있습니다. 이렇게 RSS 서비스를 위해 생성되는 XML 파일을 RSS 피드(feed), 또는 웹피드(webfeed), RSS 스트림(RSS stream), RSS 채널(RSS channel)등 다양한 이름으로 부르는데, 이 중 피드라는 말을 가장 많이 사용합니다. 만약 특정 사이트의 RSS를 구독하고 싶다고 한다면, RSS 피드의 주소를 반드시 알아야 되는 것이죠.
XML은 기계는 물론 사람도 읽을 수 있는 형태이기 때문에, RSS XML만 있어도 어느 정도 사이트의 정보를 알아낼 수 있기는 합니다. 하지만 이를 보다 알아보기 쉽고 깔끔하게 표현하기 위해 RSS XML을 읽어들이는 여러 프로그램들이 존재합니다. 이를 RSS 리더, 또는 RSS 수집기(aggregator)라고 하는데, 자신의 컴퓨터에 깔아서 쓰는 형태의 프로그램들도 무수히 많으며, 모질라 파이어폭스(Mozilla Firefox)의 라이브북마크(Live Bookmark)나 익스플로러(Internet Explorer) 7.0 버전처럼 브라우저에서 아예 RSS 리더를 지원하는 경우도 있습니다.
RSS는 컨텐츠 배포와 수집 방식으로 이미 큰 흐름이 되어가고 있습니다. 물론 현재 RSS 구독자들이 가지고 있는 피드들의 대부분 블로그이기는 하지만, 반드시 블로그가 아니더라도 인터넷 언론 같이 RSS 서비스를 하고 있는 곳도 많으며 게시판 같이 컨텐츠가 쌓이는 곳이라면 어디서나 RSS를 지원하려 하고 있습니다. 어쩌면 이러한 추세가 사용자의 귀차니즘을 잘 이해한 결과일런지도 모르지만, 동시에 생산한 컨텐츠를 보다 쉽게 배포할 수 있고 컨텐츠들의 재편집을 통해 새로운 컨텐츠를 만들어낼 수도 있다는 점에 있어서, 단순한 배포 기술 이상의 의미를 지닐 수도 있을 것 같다는 생각입니다.
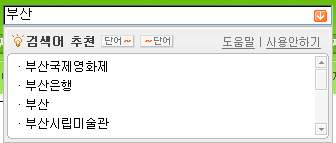 저는 개인적으로 국내의 검색 포털을 잘 사용하지 않습니다. 정보를 가장한 광고들도 물론 짜증나지만, 무엇보다 검색 결과의 질이 별로이기 때문이죠. 하지만 블로그나 커뮤니티의 정보를 찾기 위해 어쩔 수 없이 검색 포털을 이용할 때가 있습니다. 그런데 언젠가 (벌써 꽤 오래 전의 이야기가 되어 버렸지만) N모 사의 검색 서비스를 사용하다가 깜짝 놀란 적이 있었습니다. 검색어 입력창에 검색어를 입력하는 도중에 추천 검색어가 아래에 있는 박스에 뜨는 것이 아니겠어요. 보통 어플리케이션에서 이런 기능은 별 것 아닐 수 있겠지만, 일반적인 웹어플리케이션에서는 이런 기능을 수행하기가 거의 불가능에 가깝기 때문이죠.
저는 개인적으로 국내의 검색 포털을 잘 사용하지 않습니다. 정보를 가장한 광고들도 물론 짜증나지만, 무엇보다 검색 결과의 질이 별로이기 때문이죠. 하지만 블로그나 커뮤니티의 정보를 찾기 위해 어쩔 수 없이 검색 포털을 이용할 때가 있습니다. 그런데 언젠가 (벌써 꽤 오래 전의 이야기가 되어 버렸지만) N모 사의 검색 서비스를 사용하다가 깜짝 놀란 적이 있었습니다. 검색어 입력창에 검색어를 입력하는 도중에 추천 검색어가 아래에 있는 박스에 뜨는 것이 아니겠어요. 보통 어플리케이션에서 이런 기능은 별 것 아닐 수 있겠지만, 일반적인 웹어플리케이션에서는 이런 기능을 수행하기가 거의 불가능에 가깝기 때문이죠.
전통적인 웹 처리 방식은 웹서버와 브라우저 사이의 동기적인 통신에 의해 구성됩니다. 이전에 XSS를 설명할 때 잠깐 언급한 바가 있지만, 페이지를 하나를 띄우려면 브라우저에서 웹서버로 페이지에 대한 요청을 보내고 웹서버는 이를 처리하여 페이지를 응답합니다. 이 응답결과를 브라우저는 받아 화면에 표시해 주는 것이죠. 중요한 것은 이런 과정이 동기적으로 이루어진다는 것인데, 이는 브라우저가 웹서버가 응답을 보내줄 때까지 기다려야한다는 의미입니다. 잘못된 주소에 요청을 보내면 브라우저에 곧바로 에러가 뜨지 않고 일정 시간을 기다린 후 404 Not Found 에러가 뜨는 것도 이러한 동기적 통신에 의해 처리가 이루어지기 때문이죠.
이러한 특성 때문에 웹어플리케이션에서 어떤 기능을 수행하려면 언제나 페이지 전체를 로딩해야 합니다. 아무리 간단한 정보라도 웹서버에 일단 요청을 보내면 전체 HTML을 다 받아야만 응답이 마무리되게 되어 있으므로 웹서버는 전체 HTML을 전부 브라우저에 보내주어야 하는 것이죠. 하지만 N사의 추천검색어 박스나 구글의 서제스트(Suggest : http://www.google.com/webhp?complete=1&hl=en) 서비스는 페이지를 로딩시키지 않습니다. 전통적인 웹어플리케이션에서 페이지 로딩없이 이런 기능을 가능하게 하려면 모든 추천검색어를 지닌 사전 데이터를 사용자 PC에 미리 깔아놓고 이를 참조하는 것밖에 방법이 없습니다. 그러나 Ajax를 통해 페이지를 보다 동적으로 만들어주는 이러한 기능들이 가능하다는 사실을 나중에야 알게 되었죠.
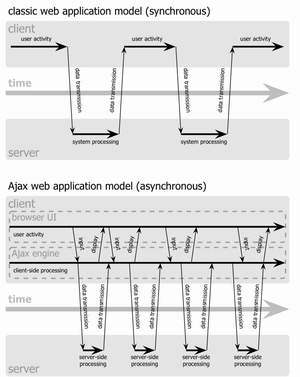 Ajax는 Asynchronous JavaScript and XML의 약자로 제시 제임스 가렛(Jesse James Garrett)이라는 사람이 처음 제안한 웹 처리 방식입니다. 정확하게 말하자면 Ajax는 어떤 특정한 기술을 가리키는 말이 아니라 자바스크립트와 XML을 사용하여 웹서버와 통신하는 처리 방식(또는 플랫폼)을 의미하죠. 전통적인 웹 처리 방식이 HTML을 결과로 받는다면, Ajax에서는 XMLHttpRequest 객체를 사용하여 XML로 결과를 받습니다. 브라우저에서는 결과로 받은 XML을 적당히 가공해서 HTML로 보여주는 것이죠. 여기서 중요한 단어는 Asynchronous, 즉 비동기입니다. Ajax를 통해 브라우저가 웹서버에 요청을 보내면 응답이 올 때까지 기다릴 필요가 없습니다. 대신 XMLHttpRequest 객체의 상태 체크를 통해 웹서버로부터 응답이 왔을 때를 알 수 있고, 이 때 이에 맞는 처리를 해 주면 되는 것이죠. 이런 방식으로 페이지 전체를 로딩할 필요없이 HTML의 일부분만을 변경할 수 있습니다. 이를 위해 Ajax에서는 DOM(Document Object Model)을 사용하는데, 이에 대해서는 나중에 설명하도록 하겠습니다.
Ajax는 Asynchronous JavaScript and XML의 약자로 제시 제임스 가렛(Jesse James Garrett)이라는 사람이 처음 제안한 웹 처리 방식입니다. 정확하게 말하자면 Ajax는 어떤 특정한 기술을 가리키는 말이 아니라 자바스크립트와 XML을 사용하여 웹서버와 통신하는 처리 방식(또는 플랫폼)을 의미하죠. 전통적인 웹 처리 방식이 HTML을 결과로 받는다면, Ajax에서는 XMLHttpRequest 객체를 사용하여 XML로 결과를 받습니다. 브라우저에서는 결과로 받은 XML을 적당히 가공해서 HTML로 보여주는 것이죠. 여기서 중요한 단어는 Asynchronous, 즉 비동기입니다. Ajax를 통해 브라우저가 웹서버에 요청을 보내면 응답이 올 때까지 기다릴 필요가 없습니다. 대신 XMLHttpRequest 객체의 상태 체크를 통해 웹서버로부터 응답이 왔을 때를 알 수 있고, 이 때 이에 맞는 처리를 해 주면 되는 것이죠. 이런 방식으로 페이지 전체를 로딩할 필요없이 HTML의 일부분만을 변경할 수 있습니다. 이를 위해 Ajax에서는 DOM(Document Object Model)을 사용하는데, 이에 대해서는 나중에 설명하도록 하겠습니다.
앞에서 언급한 N사의 추천검색어를 Ajax로 구현한다고 생각해봅시다. "부산국제영화제"를 검색하는 경우, 일단 "부산"이라고 치는 순간 XMLHttpRequest를 통해 "부산"이라는 키워드를 웹서버에 전송합니다. 웹서버는 "부산"에 해당하는 추천검색어를 XML로 브라우저에 돌려주고, 브라우저는 이를 받아 자바스크립트를 통해 박스를 만들고 추천검색어를 이 박스에 써 줍니다. 이런 과정을 통해 페이지 전체를 다시 로딩하는 수고를 하지 않고도 동적인 페이지를 구성할 수 있게 되는 것이죠.
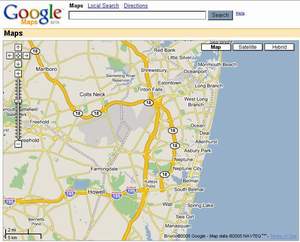 현재 XMLHttpRequest를 사용하여 서비스를 구현하는 곳은 매우 많습니다. 페이지를 다시 로딩하지 않았는데도 뭔가 복잡한 동작들을 수행하는 곳 중 상당수는 Ajax를 쓰고 있다고 생각하셔도 좋습니다. 이런 Ajax를 효과적으로 사용하고 있는 곳 중 하나는 바로 구글입니다. 아까 잠깐 언급했던 서제스트(Suggest)도 그렇지만, 지도 서비스를 하는 구글맵(http://maps.google.com/)은 Ajax를 매우 잘 사용한 모범적인 예라고 할 수 있습니다. 구글맵을 접속해보면 아시겠지만, '뭐를 설치하시겠습니까?'라는 질문을 받지 않습니다. 구글맵은 Active-X나 자바 애플릿 등을 사용하지 않고, 오로지 자바스크립트만으로 구성되어 있습니다. 당연히 처음 지도를 로드할 때에는 화면에 보이는 영역의 이미지를 웹서버로부터 불러오지만, 지도를 드래그해서 전후좌우로 움직일 때 페이지 전체를 로딩하지 않고도 새로운 이미지를 받아오는 것을 확인할 수 있습니다. 이런 방식으로 모든 지도의 이미지를 PC에 다운받는 수고를 할 필요없이 실시간으로 웹서버를 통해 지도의 이미지를 가져올 수 있죠.
현재 XMLHttpRequest를 사용하여 서비스를 구현하는 곳은 매우 많습니다. 페이지를 다시 로딩하지 않았는데도 뭔가 복잡한 동작들을 수행하는 곳 중 상당수는 Ajax를 쓰고 있다고 생각하셔도 좋습니다. 이런 Ajax를 효과적으로 사용하고 있는 곳 중 하나는 바로 구글입니다. 아까 잠깐 언급했던 서제스트(Suggest)도 그렇지만, 지도 서비스를 하는 구글맵(http://maps.google.com/)은 Ajax를 매우 잘 사용한 모범적인 예라고 할 수 있습니다. 구글맵을 접속해보면 아시겠지만, '뭐를 설치하시겠습니까?'라는 질문을 받지 않습니다. 구글맵은 Active-X나 자바 애플릿 등을 사용하지 않고, 오로지 자바스크립트만으로 구성되어 있습니다. 당연히 처음 지도를 로드할 때에는 화면에 보이는 영역의 이미지를 웹서버로부터 불러오지만, 지도를 드래그해서 전후좌우로 움직일 때 페이지 전체를 로딩하지 않고도 새로운 이미지를 받아오는 것을 확인할 수 있습니다. 이런 방식으로 모든 지도의 이미지를 PC에 다운받는 수고를 할 필요없이 실시간으로 웹서버를 통해 지도의 이미지를 가져올 수 있죠.
Ajax를 사용하여 할 수 있는 일은 무궁무진합니다. 비단 Ajax 뿐만 아니라 매크로미디어(Macromedia)의 Flex나 차세대 윈도인 롱혼(Longhorn)에서 지원할 XAML, 모질라 기반 브라우저에서 지원하는 XUL 등 대안적인 방식들의 등장으로 인해 어쩌면 웹어플리케이션의 모습은 일반 PC에서 사용하는 오피스 같은 어플리케이션과 비슷하게 될 수도 있을 것 같습니다. 이 가운데 Ajax는 웹표준기구인 W3C의 표준안을 기반으로 하고 있으며 XMLHttpRequest 역시 표준으로 지원할 예정이라는 점에 있어 장점을 지니고 있죠. Ajax를 지원하는 웹브라우저 역시 늘고 있기 때문에, 앞으로 Ajax를 사용하는 웹어플리케이션을 쉽게 접할 수 있으리라 생각합니다.
다만 웹어플리케이션의 모습이 화려해지고 풍부해진다고 무조건 좋은 현상이라고 할 수만은 없습니다. 매크로미디어 플래시가 멋진 외관과 다양한 기능을 제공하는 반면 장애인들의 접근성을 떨어뜨리고 많이 사용하지 않는 브라우저를 쓰는 유저들을 배제시키는 것처럼 말이죠. Ajax를 통한 기획/개발을 하는 사람은 언제나 이러한 소수자에 대한 고려를 잊지 말아야 할 것입니다.

댓글 목록
관리 메뉴
본문
레니. 혹시 네트워커에 글 쓰느라 너무 소진해서 블로깅 잘 안하는 거 아니오?? (궁금....)부가 정보
관리 메뉴
본문
알엠//게을러서 그런게죠-_-;; 한참 바쁘다가 조금 한가해지니 늘어지네요.ㅎㅎ부가 정보
관리 메뉴
본문
레니/ 흐흐 오랜만이요. 한가한거였군요. 되게 바쁜줄 알고 말도 안걸구 그랬는데.부가 정보
관리 메뉴
본문
달군//프로젝트 일정이 연기되어서.ㅎㅎ 근데 후유증이 심각하오-_-;;;부가 정보