최근 글 목록
-
- 트위터 맞팔 논쟁
- 레니
- 2010
-
- 21세기판 골드러시 - 데이터...(1)
- 레니
- 2008
-
- 이런 스팸메일
- 레니
- 2008
-
- 구글의 새 브라우저, 크롬 (...(6)
- 레니
- 2008
-
- 다크 나이트 (The Dark Knig...(5)
- 레니
- 2008
66개의 게시물을 찾았습니다.




 요즘 포털들의 때아닌 이메일 서비스 경쟁이 한창입니다. 몇 년 전 G메일의 등장으로 인해 촉발된 기가바이트(GB) 단위 메일 서비스 경쟁을 마지막으로, 그간 이메일 서비스 시장는 특별한 변화가 없이 평온한 나날을 보내고 있었습니다. 그러다 최근들어 난데없이 이메일 서비스 시장은 다시금 포털들의 치열한 각축장이 되고 있는 것이죠.
요즘 포털들의 때아닌 이메일 서비스 경쟁이 한창입니다. 몇 년 전 G메일의 등장으로 인해 촉발된 기가바이트(GB) 단위 메일 서비스 경쟁을 마지막으로, 그간 이메일 서비스 시장는 특별한 변화가 없이 평온한 나날을 보내고 있었습니다. 그러다 최근들어 난데없이 이메일 서비스 시장은 다시금 포털들의 치열한 각축장이 되고 있는 것이죠. 포털이든 특정 사이트든 간에, 사용자가 한 번 로그인을 하고 나면 그 다음부터 사용자는 로그인 된 상태로 돌아다닐 수 있게 됩니다. 이는 웹서버와 사용자의 브라우저 사이에 세션Session이 생성되기 때문입니다. 웹이 기반하고 있는 HTTP 프로토콜은 기본적으로 요청(사용자)-응답(웹서버)의 연속으로 이루어지는데, 통상적인 HTTP 통신에서는 이러한 요청이나 응답의 결과들을 별도로 저장하지 않습니다. 하지만 로그인 정보 같이 특정한 정보를 사용자가 요청할 때마다 저장해서 사용해야 하는 경우가 있는데, 이 때를 위해 사용되는 것이 바로 쿠키Cookie와 세션입니다.
포털이든 특정 사이트든 간에, 사용자가 한 번 로그인을 하고 나면 그 다음부터 사용자는 로그인 된 상태로 돌아다닐 수 있게 됩니다. 이는 웹서버와 사용자의 브라우저 사이에 세션Session이 생성되기 때문입니다. 웹이 기반하고 있는 HTTP 프로토콜은 기본적으로 요청(사용자)-응답(웹서버)의 연속으로 이루어지는데, 통상적인 HTTP 통신에서는 이러한 요청이나 응답의 결과들을 별도로 저장하지 않습니다. 하지만 로그인 정보 같이 특정한 정보를 사용자가 요청할 때마다 저장해서 사용해야 하는 경우가 있는데, 이 때를 위해 사용되는 것이 바로 쿠키Cookie와 세션입니다.
 DRM 에서 가장 중요한 부분은 암호화 기술입니다. DRM 인증을 통하지 않은 사용자는 사용할 수 없도록 파일을 암호화시켜 변형해야 하고, 만약 사용자가 인증을 통과하면 이를 다시 복원시킬 수 있어야 하기 때문에, DRM의 가장 핵심적인 기술이 여기에 있다고 해도 과언이 아닙니다. 여기에 암호화된 파일을 다시 원래의 파일로 복원시켜야 하기 때문에 반드시 키가 필요합니다. 만약 그 키가 패스워드처럼 단일한 키로 되어 있다면, 그 패스워드가 유출되었을 경우 거의 모든 사람이 DRM을 무시하고 컨텐츠를 사용할 수 있게 되어 버립니다. 그래서 보통 사용자마다 서로 다른 키를 통해 암호화하는 방법을 씁니다. 예전에 많이 사용하던 방식은 사용자의 컴퓨터마다 있는 고유번호를 쓰는 것인데요, 예를 들면 CPU의 일련번호나 랜카드의 맥어드레스 등을 적절히 변형시켜 사용하곤 했습니다. 하지만 컴퓨터의 일련번호는 다른 사람이 쉽게 알아낼 수 있는 번호이기 때문에 보안성이 떨어진다는 단점이 있습니다. 그래서 요즘엔 사용자마다 공인인증서 같이 별도의 키를 발급하고 이를 컴퓨터 어딘가에 내장시켜 놓고 쓰는 방식이 일반적입니다. 이렇게 개인키를 통해 암호화 했을 경우에는 제3자의 컴퓨터에서는 복제된 컨텐츠를 사용할 수 없다는 장점이 있습니다.
DRM 에서 가장 중요한 부분은 암호화 기술입니다. DRM 인증을 통하지 않은 사용자는 사용할 수 없도록 파일을 암호화시켜 변형해야 하고, 만약 사용자가 인증을 통과하면 이를 다시 복원시킬 수 있어야 하기 때문에, DRM의 가장 핵심적인 기술이 여기에 있다고 해도 과언이 아닙니다. 여기에 암호화된 파일을 다시 원래의 파일로 복원시켜야 하기 때문에 반드시 키가 필요합니다. 만약 그 키가 패스워드처럼 단일한 키로 되어 있다면, 그 패스워드가 유출되었을 경우 거의 모든 사람이 DRM을 무시하고 컨텐츠를 사용할 수 있게 되어 버립니다. 그래서 보통 사용자마다 서로 다른 키를 통해 암호화하는 방법을 씁니다. 예전에 많이 사용하던 방식은 사용자의 컴퓨터마다 있는 고유번호를 쓰는 것인데요, 예를 들면 CPU의 일련번호나 랜카드의 맥어드레스 등을 적절히 변형시켜 사용하곤 했습니다. 하지만 컴퓨터의 일련번호는 다른 사람이 쉽게 알아낼 수 있는 번호이기 때문에 보안성이 떨어진다는 단점이 있습니다. 그래서 요즘엔 사용자마다 공인인증서 같이 별도의 키를 발급하고 이를 컴퓨터 어딘가에 내장시켜 놓고 쓰는 방식이 일반적입니다. 이렇게 개인키를 통해 암호화 했을 경우에는 제3자의 컴퓨터에서는 복제된 컨텐츠를 사용할 수 없다는 장점이 있습니다. 하지만 암호화시킨 컨텐츠를 다시 복호화 한다는 것은, 다른 누군가가 암호를 깰 수 있다는 말입니다. 실제로 널리 사용되는 DRM은 끊임없는 해킹 시도를 당해 왔고, 실제로 해킹에 성공한 사례들 도 꽤 있습니다. 또한 DRM은 전세계적인 표준이 없고 웬만한 큰 기업들은 자기만의 DRM을 가지고 있어서 이들 사이의 호환이 되지 않습니다. 애플 것이 다르고 M$ 것이 다르고 소니 것이 다르기 때문에, 사용자는 여러모로 불편함을 감수할 수밖에 없는 것이죠. (물론 M$의 영향력이 막대한 한국은 미디어플레이어를 기반으로 한 WMRM을 많이 사용하지만요.)
하지만 암호화시킨 컨텐츠를 다시 복호화 한다는 것은, 다른 누군가가 암호를 깰 수 있다는 말입니다. 실제로 널리 사용되는 DRM은 끊임없는 해킹 시도를 당해 왔고, 실제로 해킹에 성공한 사례들 도 꽤 있습니다. 또한 DRM은 전세계적인 표준이 없고 웬만한 큰 기업들은 자기만의 DRM을 가지고 있어서 이들 사이의 호환이 되지 않습니다. 애플 것이 다르고 M$ 것이 다르고 소니 것이 다르기 때문에, 사용자는 여러모로 불편함을 감수할 수밖에 없는 것이죠. (물론 M$의 영향력이 막대한 한국은 미디어플레이어를 기반으로 한 WMRM을 많이 사용하지만요.) UCC라는 단어를 아마 한 번쯤은 들어보셨을 것입니다. 분명히 1년 전만 해도 이 단어는 "업계 용어"였습니다. 작년에 팀장이 뜬금없이 "혹시 UCC라는 말 아나?"라고 저한테 물었을 정도로, 아는 사람만 아는 그런 단어였죠. 일본에서 UCC 커피를 발견하고 속으로 킥킥댔던 기억도 어렴풋이 나는군요-_- 블로그나 게시판, 그리고 일부 기사 등에서 반드시 부연 설명과 함께 쓰여지던 이 말이, 어느날 갑자기 신문과 TV에 화려하게 등장하기 시작했습니다. 요즘엔 아예 부연 설명도 달아주지 않는 곳도 있을 정도로 UCC라는 단어는 상당히 일반화되었죠.
UCC라는 단어를 아마 한 번쯤은 들어보셨을 것입니다. 분명히 1년 전만 해도 이 단어는 "업계 용어"였습니다. 작년에 팀장이 뜬금없이 "혹시 UCC라는 말 아나?"라고 저한테 물었을 정도로, 아는 사람만 아는 그런 단어였죠. 일본에서 UCC 커피를 발견하고 속으로 킥킥댔던 기억도 어렴풋이 나는군요-_- 블로그나 게시판, 그리고 일부 기사 등에서 반드시 부연 설명과 함께 쓰여지던 이 말이, 어느날 갑자기 신문과 TV에 화려하게 등장하기 시작했습니다. 요즘엔 아예 부연 설명도 달아주지 않는 곳도 있을 정도로 UCC라는 단어는 상당히 일반화되었죠.
참으로 허무한 것은-아마 다들 아시겠지만-UCC가 User-Created Contents의 약자라는 겁니다. 영미권에서는 UGC(User-Generated Content)로 많이 불리기도 합니다만, 어쨌든 "사용자에 의해 생산한 컨텐츠"라는 것으로, 최근에 생긴 개념이 아니라 피씨통신의 게시판 시절부터 존재하고 있었던 것이죠. 어떻게 보면 UCC라는 개념은 전번에 소개한 적이 있는 Web 2.0과 비슷하게, 예전부터 존재하고 있었던 개념을 포장만 바꿔 그럴듯하게 만들어놓은 것일수도 있습니다. 그래서 UCC라는 단어 자체도 마케팅 용어 정도로 이해하는 사람들도 꽤 있죠.
여기서 주목할 것은 UCC라는 단어 자체가 아니라 이 단어가 널리 뜨게 된 배경입니다. UCC라는 단어가 포함된 뉴스를 검색해 보면 아시겠지만, 상당수가 동영상 UCC를 다루고 있음을 알 수 있습니다. 요즘 검색의 최대 이슈가 동영상 검색이라는 점과 최근 구글에 인수된 유튜브(YouTube)를 생각해 볼 때, 예전에 비해 동영상이라는 포맷의 비중이 매우 커졌음을 알 수 있죠.
동영상의 급부상은 충분히 수긍갈만한 현상입니다. 어떤 내용을 전달하려 할 때 동영상만큼 직관적이고 분명한 수단은 많지 않을 것입니다. 하지만 동영상이 대중화되기 위해서는 여러가지 환경적인 제약이 존재했는데, 첫째는 동영상을 부담없이 끊기지 않게 볼 수 있는 충분한 네트워크 환경의 조성되어야 했었고, 둘째는 동영상을 제작하기 위해서는 캠코더 같은 장비와 프리미어 등의 동영상 편집툴을 다룰 수 있는 상당한 고급기술이 필요한 것이라 생산자가 극히 제한적일 수밖에 없었던 것입니다. 전자의 제약은 비약적으로 발전하는 네트워크 기술에 의해 극복되고 있었지만, 후자의 제약만큼은 만만치 않은 것이었죠. 동영상 UCC가 각광받는다는 것은 이런 제약들을 넘어설 수 있는 기반이 마련되고 있다는 말로 이해 가능합니다. 멀티미디어 작업에 능숙한 유저들이 늘어나고 있을 뿐만 아니라, 쉽고 간단한 동영상 제작툴도 많이 나오고 있기 때문에 이런 변화들이 가능한 것이겠죠. 이런 변화는 비단 동영상 뿐만이 아니라 음악이나 이미지 등 전반적인 UCC에 걸쳐 일어나고 있는데요, UCC가 주목받게 된 데는 이렇게 두터워진 생산자 층이 큰 역할을 담당하지 않았나 생각합니다. VI 에디터 만큼이나 어려웠던 하이텔의 문서작성기(당시 글 하나 올리는데는 상당한 난관을 돌파해야 했습니다)를 기억하시는 분이라면, 지금의 문서/이미지/동영상 편집기들은 분명히 보다 많은 사람들을 생산의 장으로 끌어들일 수 있을테니깐요.
동영상 UCC가 각광받는다는 것은 이런 제약들을 넘어설 수 있는 기반이 마련되고 있다는 말로 이해 가능합니다. 멀티미디어 작업에 능숙한 유저들이 늘어나고 있을 뿐만 아니라, 쉽고 간단한 동영상 제작툴도 많이 나오고 있기 때문에 이런 변화들이 가능한 것이겠죠. 이런 변화는 비단 동영상 뿐만이 아니라 음악이나 이미지 등 전반적인 UCC에 걸쳐 일어나고 있는데요, UCC가 주목받게 된 데는 이렇게 두터워진 생산자 층이 큰 역할을 담당하지 않았나 생각합니다. VI 에디터 만큼이나 어려웠던 하이텔의 문서작성기(당시 글 하나 올리는데는 상당한 난관을 돌파해야 했습니다)를 기억하시는 분이라면, 지금의 문서/이미지/동영상 편집기들은 분명히 보다 많은 사람들을 생산의 장으로 끌어들일 수 있을테니깐요.
이러한 UCC 시대에는 생산자들의 자발적인 참여 구조가 매우 중요하게 됩니다. 사람들에게 인정받기 위해서든, 즐거움을 선사하기 위해서든, 또는 한 몫 잡아보기 위해서든, 동기가 어떻든 간에 생산하고 참여하려는 사람들이 존재해야 하고, 생산된 UCC에 쉽게 접근할 수 있는 통로가 확보되어야 합니다. 하지만 아직은 펌글이 넘쳐나고 있는 한국의 블로그들과 자신의 마당 안에서만 자유로이 놀 것을 허용하는 닫힌 포털의 구조에서 이러한 참여 구조가 제대로 정착될 지는 의문입니다. 임정현 씨가 YouTube에 캐논을 올려놓지 않고 국내 포털의 한 블로그에 올렸다면, 이 컨텐츠는 해당 포털 안에서는 유명해질 수 있겠지만 외부로 알려지는데는 꽤 시간이 걸릴 것이고, 알려지더라도 펌에 펌을 거쳐 원작자가 누군지도 불명확한 채 네트워크에서 떠돌 가능성이 크겠죠. 따지고 보면 포털들은 UCC 시대의 화려한 만개를 꿈꾸고 있지만 한편으로는 그것을 가로막고 있는, 역설적인 상황이라고도 할 수 있겠습니다.
UCC는 직관적으로 이해하기 어렵지 않은 개념임에도 불구하고, 용어 자체를 엄밀하게 정의하기 위해서는 아직 해명되지 않은 부분이 꽤 있습니다. 그럼에도 이제까지 그랬듯이 업체들은 새로운 수익모델로서 UCC를 밀려 할 것이고, 이는 사용자에게 컨텐츠 생산 비용을 전가함과 동시에 UCC 풀의 닫힌 구조를 강화하는 방향으로 나아가지 않을까 우려됩니다. 또한 강화되어가는 저작권의 개념과 UCC 생산자의 자기 통제가 필요하다는 부분에 있어서 역시 UCC 열풍을 가로막는 요인이 될 수 있을 것입니다.
UCC에 대한 한국판 위키피디아의 약간은 자조적인 설명과 UGC에 대한 영문판 위키피디아의 희망섞인 설명이 이루는 대조가 상당히 묘한 느낌을 주는 것 같군요.
 누군가의 말대로, 네트는 광대합니다. 그래서 그런지 네트워크를 흔히 우주에 많이 비유하곤 하죠. 물론 전 세계에 흩어져있는 서버와 클라이언트 컴퓨터(호스트)들이 밤 하늘의 별들만큼 많기야 하겠냐만은, 네트워크가 이루는 세상은 그 크기를 미루어 짐작할 수 없을만큼 광대한 공간이라는 사실만큼은 틀림없는 것 같습니다.
누군가의 말대로, 네트는 광대합니다. 그래서 그런지 네트워크를 흔히 우주에 많이 비유하곤 하죠. 물론 전 세계에 흩어져있는 서버와 클라이언트 컴퓨터(호스트)들이 밤 하늘의 별들만큼 많기야 하겠냐만은, 네트워크가 이루는 세상은 그 크기를 미루어 짐작할 수 없을만큼 광대한 공간이라는 사실만큼은 틀림없는 것 같습니다.
하지만 우주에도 은하계가 있고 행성계가 있듯이, 전체 네트워크 상에 호스트들이 무질서하게 흩어져 있는 것처럼 보여도 실은 나름의 체계가 있습니다. 같은 사무실에서 사용하는 PC들이나 특정한 망에 가입되어 있는 사용자들의 컴퓨터는 네트워크 우주 안에서 하나의 소우주를 이루고 있죠. 이들은 단일한 인트라넷으로 묶이기도 하고, 일정한 IP 대역 안에서 IP를 부여받습니다. 결국 광대한 전체 네트워크는 이러한 소우주 네트워크들이 모여서 만들어내는 것이지요.
게이트웨이는 특정한 네트워크와 다른 네트워크의 연결점이라 할 수 있습니다. 게이트웨이gateway의 사전적인 정의와 같이 일종의 관문 역할을 수행하는 셈이죠. 다른 말로 하면, 특정 네트워크의 게이트웨이는 그 네트워크의 시작점이라고도 할 수 있습니다. 보통 게이트웨이 주소를 잡을 때 끝자리가 1번으로 잡는 경우가 많은데요(xxx.xxx.xx.1), 게이트웨이가 네트워크의 시작점이라는 상징적인 의미라고도 볼 수 있죠.
예를 들면, 제가 관리하는 www.abc.com이라는 서버의 IP 주소가 211.255.23.39라고 하고, 그 서버가 속해있는 네트워크의 게이트웨이 주소가 211.255.23.1이라고 합시다. 만약 www.abc.com으로 페이지 접속 요청을 보냈을 때, 이 요청은 무조건 게이트웨이를 먼저 통과하여 제 서버로 전달됩니다. 웹페이지를 응답할 때에도 마찬가지로 게이트웨이를 통과하여 요청한 사용자의 PC로 전달하게 되죠. 이렇게 게이트웨이가 하는 역할이 관문이다보니, 통로로서의 역할 뿐만 아니라 검문소의 역할을 하기도 합니다. 그래서 보안이 필요한 네트워크에서의 게이트웨이는 방화벽의 역할을 수행하기도 하죠. 네트워크를 통해 들어오고 나가는 데이터들(패킷packet이라고 합니다)을 전부 관리할 수 있기 때문에, 악성코드나 특정 데이터에 대해 쉽게 걸러낼 수가 있습니다.
이렇게 게이트웨이가 하는 역할이 관문이다보니, 통로로서의 역할 뿐만 아니라 검문소의 역할을 하기도 합니다. 그래서 보안이 필요한 네트워크에서의 게이트웨이는 방화벽의 역할을 수행하기도 하죠. 네트워크를 통해 들어오고 나가는 데이터들(패킷packet이라고 합니다)을 전부 관리할 수 있기 때문에, 악성코드나 특정 데이터에 대해 쉽게 걸러낼 수가 있습니다.
약간은 생소한 게이트웨이에 비해 DNS Domain Name System, 즉 도메인 서버에 대해서는 많이 알고 계실 듯 합니다. 도메인은 네트워크 상의 특정 위치를 결정지어주는 IP 주소 대신 쓸 수 있는 이름입니다. 인터넷 서핑을 할 때 브라우저를 켜고 주소를 치게 되는데, 이 주소가 바로 도메인입니다. 아까의 예에서, 사실 www.abc.com을 보고 싶을 때, 211.255.23.39라고 입력해도 같은 내용이 나옵니다. www.abc.com과 211.255.23.39은 둘 다 제가 관리하는 서버의 네트워크 상에서 위치를 나타내는 주소이기 때문이죠. 하지만 숫자 네 개로 이루어진 IP에 비해 도메인은 기억하기가 훨씬 용이하기 때문에, IP 주소를 일일히 집어넣는 수고 대신에 도메인으로 간단하게 요청을 보내는 것이죠.
DNS가 하는 역할은 www.abc.com이 211.255.23.39라는 점을 알려주는 일입니다. 즉, 특정 도메인을 IP 주소에 매핑mapping하는 것이죠. TCP/IP 네트워크에서는 IP가 특정 네트워크 포인트를 알려주는 주소라고 했습니다. 만약 도메인을 입력해서 특정 포인트를 찾으려고 한다면, 먼저 DNS가 도메인을 IP 주소로 번역하고, 그 IP 주소로 요청을 날리게 되는 것이죠.
재미있는 것은, 도메인과 IP 주소의 데이터베이스인 DNS를 정해진 누군가가 관리하지는 않는다는 점입니다. 만약 전세계에 DNS 서버가 한 대만 존재하고 있다면, 만약 그 서버가 다운되었을 때 도메인 이름을 모른다면 어떠한 네트워크 포인트에도 접속할 수 없을 것입니다. 그래서 DNS는 세계 도처에 존재하며, 하나의 DNS 서버가 못 쓰게 되거나 효율이 좋지 않다면 다른 DNS를 참조해서 IP 주소를 얻어오게 됩니다.
그렇다면 새로운 도메인이 출현했을 경우 어떤 일이 벌어질까요? 일단 www.abcd.com이라는 새 도메인을 발급받아 근처에 있는 DNS 서버에 등록했다고 가정합시다. 그 시점에서는 운좋게도 새 도메인을 등록한 DNS 서버에서 IP 주소를 받아온 사람은 www.abcd.com을 잘 찾아갈테지만, 다른 DNS 서버를 사용하고 있던 대부분의 사람들은 www.abcd.com을 주소창에 쳐도 그런 페이지는 없다는 에러밖에 볼 수 없을 것입니다. 그러나 DNS 서버들은 서로의 변경 사항을 주기적으로 교환해서 새로운 데이터베이스를 유지하도록 설계되어 있습니다. 새 도메인이 등록된 DNS 서버는 www.abcd.com에 대한 정보를 다른 DNS 서버에 전파하게 되고, 대략 하루 정도가 지나면 모든 DNS 서버가 www.abcd.com에 대한 정보를 가질 수 있게 되는 것이죠. 그래서 새 도메인을 등록하면 전체적으로 적용되는데 일정한 시간이 필요하도록 되어 있습니다. 이것은 DNS의 분산 환경 때문에 생기는 일이죠.
뭔가 단순하게 설명해놨는데, 실제로는 이보다 더 복잡한 일들이 네트워크 세계에서 일어납니다. 전세계로 통하는 복잡한 네트워크 환경에서 빠르고 정확하게 요청을 주고받게 하기 위해, 인터넷의 발전과 더불어 네트워크 기술도 계속 발전한 셈이죠. 어디서든 네트워크와 연결할 수 있는 유비쿼터스 시대니 뭐니 해도 TCP/IP의 기본적인 구조는 인터넷이 존재하는 한 남아있을 것 같습니다. 왠지 공각기동대의 전뇌 통신도 TCP/IP 기반으로 이루어지는 것이 아닐지요;;;
얼마 전에 시간을 가장 가치없게 사용하는 방법 중 상위 3위 안에 랭크될 것이 분명한 동원예비군 훈련을 갔다왔더랩니다. 제가 갔던 부대는 의정부에 있는 통신대대인데, 여기서 하는 일은 말 그대로 부대 사이의 통신을 연결하고 관리하는 일입니다. 통신대는 크게 전송조, 교환조, 유무선조로 나뉘어집니다. 저는 이 중 교환조에 속하는데, 교환조는 타 부대의 교환조와의 네트워크를 구성하여 이를 제어하고, 내부의 전화를 연결해 번호를 부여하는 등의 역할을 수행합니다. 옛날 전화에 있었다는 교환수와 비슷한 역할이라 할 수 있긴 하지만, 전화번호를 부여하고 음성 통신 뿐만 아니라 데이터 통신까지 중계한다는 점에서 보다 하는 일의 범위가 넓다고 할 수 있겠죠. 여튼 하려는 얘기는 이게 아니고-_-;;;
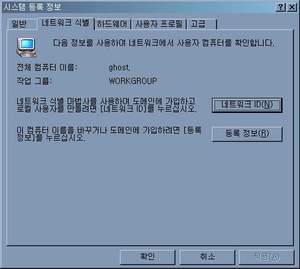 컴퓨터 사이의 네트워크도 전화와 비슷한 중계 구조를 가지고 있습니다. 집마다 있는 전화가 전화번호로서 고유하게 식별할 수 있듯이, 네트워크에 연결된 컴퓨터(정확히는 모뎀 또는 랜카드 등의 네트워크 장비)는 고유한 식별 번호를 가집니다. 예를 들면 공유 폴더로 접근할 때 사용하는 윈도의 인트라넷에서는 네트워크 아이디라는 것을 지정하도록 되어 있습니다.("시스템 등록 정보"의 "네트워크 식별" 탭에서 지정 가능합니다.) 그리고 일반적인 인터넷 연결에 사용하는 TCP/IP 네트워크에서는 바로 IP 주소라는 것을 발급하도록 되어 있죠.
컴퓨터 사이의 네트워크도 전화와 비슷한 중계 구조를 가지고 있습니다. 집마다 있는 전화가 전화번호로서 고유하게 식별할 수 있듯이, 네트워크에 연결된 컴퓨터(정확히는 모뎀 또는 랜카드 등의 네트워크 장비)는 고유한 식별 번호를 가집니다. 예를 들면 공유 폴더로 접근할 때 사용하는 윈도의 인트라넷에서는 네트워크 아이디라는 것을 지정하도록 되어 있습니다.("시스템 등록 정보"의 "네트워크 식별" 탭에서 지정 가능합니다.) 그리고 일반적인 인터넷 연결에 사용하는 TCP/IP 네트워크에서는 바로 IP 주소라는 것을 발급하도록 되어 있죠.
TCP/IP는 인터넷의 가장 기본적인 프로토콜입니다. 프로토콜은 (전에도 한 번 설명했지만) 통신을 위해 정의된 규약입니다. TCP(Transmission Control Protocol)라는 프로토콜과 IP(Internet Protocol)라는 프로토콜이 결합된 것이 TCP/IP로서, 웹(WWW)에 사용되는 HTTP, 원격 컴퓨터 제어를 위한 텔넷(Telnet), 파일 전송을 위한 FTP, 메일에 사용되는 SMTP등이 TCP/IP를 사용하는 프로토콜들입니다. 물론 인터넷 통신을 하기 위해서는 TCP/IP 프로그램이 반드시 필요합니다. 당연히 윈도나 리눅스 등의 거의 모든 OS에는 TCP/IP를 사용하기 위한 프로그램이 기본적으로 깔려 있죠. 보통 IP 주소를 잡기 위해 들어가는 설정 프로그램도 이런 제어 프로그램의 일부입니다.
IP 주소는 현재 IPv4라는 방식이 사용되고 있습니다. "211.255.23.35" 같이 0~255 사이의 수를 4개 붙여서 사용하는 것이 IPv4의 방식입니다. IP 주소는 앞에서 언급했듯이 전화번호같이 네트워크 상에서 특정 컴퓨터(호스트host)를 인식 가능하게 하는 고유한 번호입니다. 따라서 전세계의 모든 컴퓨터에 IP 주소를 붙여주어야 한다고 하면, 이론상 각 자리마다 256개의 숫자가 들어갈 수 있으므로 256x256x256x256=4,294,967,296, 즉 대략 43억 대의 컴퓨터가 붙을 수 있게 되는 셈이죠.
 하지만 복잡한 IP 주소 부여 법칙에 의해 실제로는 이보다 적은 수의 IP 주소만이 사용할 수 있으며, 특히 각 국가마다 할당된 IP 주소의 영역이 제한되어 있기 때문에 IP 주소는 지금도 매우 부족한 상황에 놓여 있죠. 그래서 방화벽으로 구성된 폐쇄적인 네트워크에서는 보안상의 이유와 더불어 사용 가능한 IP 주소를 늘이기 위해 내부에서만 사용할 수 있는 IP를 따로 정의해 쓰기도 하고, 하나의 IP를 여러대의 컴퓨터가 공유하기도 합니다. 가장 흔한 예가 인터넷 공유기를 사용해 2대 이상의 컴퓨터를 붙여 쓰는 경우인데요, 이 경우에는 공유기가 라우터의 역할을 수행하여 별도의 IP를 각 컴퓨터에 붙여줍니다.
하지만 복잡한 IP 주소 부여 법칙에 의해 실제로는 이보다 적은 수의 IP 주소만이 사용할 수 있으며, 특히 각 국가마다 할당된 IP 주소의 영역이 제한되어 있기 때문에 IP 주소는 지금도 매우 부족한 상황에 놓여 있죠. 그래서 방화벽으로 구성된 폐쇄적인 네트워크에서는 보안상의 이유와 더불어 사용 가능한 IP 주소를 늘이기 위해 내부에서만 사용할 수 있는 IP를 따로 정의해 쓰기도 하고, 하나의 IP를 여러대의 컴퓨터가 공유하기도 합니다. 가장 흔한 예가 인터넷 공유기를 사용해 2대 이상의 컴퓨터를 붙여 쓰는 경우인데요, 이 경우에는 공유기가 라우터의 역할을 수행하여 별도의 IP를 각 컴퓨터에 붙여줍니다.
라우터는 독립된 네트워크의 시작점이 되는 장비로서 보통 게이트웨이의 역할을 수행합니다. IP주소를 직접 잡아 보신 분들은 아시겠지만 IP주소를 설정하기 위해 IP주소는 물론이고 게이트웨이 주소와 DNS 주소를 넣어줘야 하는데, 그 게이트웨이 주소가 일반적으로 이 라우터의 주소입니다. 게이트웨이와 DNS에 대한 설명은 조금 길어지므로 다음에 다루도록 하겠습니다.
만약 자신의 컴퓨터가 네트워크에 등록되어 있는데 IP 주소를 알아야 하는 경우가 있습니다. 물론 컴퓨터의 설정 정보를 뒤져보면 어딘가에 IP 주소를 정의해 놓은 곳이 있겠죠. 그러나 그 곳을 찾기 귀찮거나 IP를 자동 설정으로 해 놓으신 분들은 TCP/IP 프로그램을 이용하여 쉽게 IP 주소를 알아낼 수 있습니다. 윈도 2000이나 윈도 XP 이상을 사용하시는 분들은 윈도의 커맨드 창에서 "ipconfig"를 입력하시면 관련 정보가 쉽게 나타납니다.(커맨드 창을 띄우시려면 윈도의 시작 ->실행에서 "cmd"를 입력하시면 되죠.) 리눅스 등 유닉스 계열의 OS에서는 일반적으로 /sbin/ifconfig를 실행하시면 관련 정보가 나옵니다.
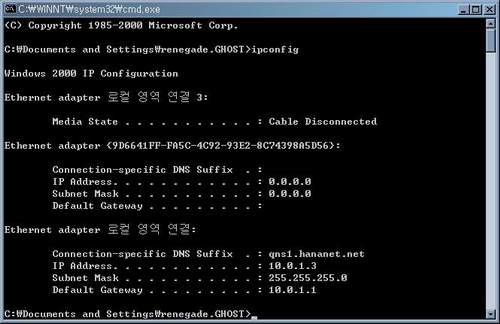
위에 보면 제 컴퓨터의 IP 주소는 10.0.1.3으로 나오는데요, 일반적인 IP 주소는 이런 식으로 발급되지 않습니다. 10.으로 시작하는 IP는 보통 내부에서만 사용 가능한 IP 주소인데요, 저희 집에서 공유기를 사용해 여러 컴퓨터를 연결해 사용하기 때문에 앞에서 얘기한 대로 제 공유기가 임의로 발급해 준 가짜 주소를 얻은 셈이죠. 제 컴퓨터의 진짜 IP 주소는 공유기가 가지고 있으며, 제 공유기에 연결된 컴퓨터는 외부로 접속할 경우 공유기가 갖고 있는 그 IP 주소를 모두 사용하게 됩니다.
IP 주소도 하나의 자원이다 보니 사용하는 사람이 많아질수록 점차 부족 현상이 심각해질 것임이 분명합니다. 만약 지구 상의 60억 인구가 한 대씩 네트워크에 연결된 컴퓨터만 갖고 있어도 일찌감치 IP 주소는 동이 날 터이고, 특정한 주인이 없는 컴퓨터들(예컨데 서버들)도 수없이 많이 있을테니까요. 그래서 IP 주소의 범위를 늘이기 위해 IPv6라는 방식을 도입하려 하고 있습니다. IPv6는 이론적으로 기존의 IPv4보다 65536배 많은 주소를 사용할 수 있기 때문에, 아마도 IP 주소 부족 현상은 해소 가능하다고 할 수 있겠죠. 하지만 집을 지어도지어도 내 집을 가지기가 어려운 것처럼, 왠지 IP 주소 부족 현상이 쉽게 해결될지 의심이 되는 것은...나쁜 성격 탓일까요? ;;;
얼마전 하나로텔레콤이 TV포털 서비스가 출시하면서 한바탕 논란이 일었습니다. 이제까지 인터넷 망 서비스를 하던 하나로텔레콤이 가지고 있던 인프라를 이용하여 VOD 서비스를 시작하려 하자, 기존의 방송 사업자인 케이블TV방송협회에서 반발하고 나선 것이죠. 이는 기본적으로 굴러온 돌과 박힌 돌의 대결 구도이기는 하지만, 근본적으로는 시대의 변화에 따른 방송사업자와 통신사업자의 대리전이기도 합니다.
전파나 케이블로 컨텐츠를 전달하던 방송과 유무선망으로 정보를 주고받던 통신은 지금와서 거의 구분이 무의미해졌습니다. 케이블TV 망을 통해 인터넷 서비스를 이용할 수도 있고 인터넷으로 TV를 생방송으로 볼 수 있습니다. 통신과 방송이 융합(컨버전스)을 이루어 시너지를 낼 수 있는 기반은 이미 충분히 마련되었다고 볼 수 있죠. 이런 융합을 가장 극명하게 보여주는 것이 바로 IPTV입니다. 전파나 케이블TV망이 아니라 인터넷망과 디지털TV를 이용하여 방송을 볼 수 있는 서비스가 벌써 실시되려 하고 있습니다. IPTV는 일방적으로 정보를 전달해주기만 했던 기존 방송과 달리 양방향 통신이 가능하고, 네트워크와 연결되어 여러 일을 동시에 할 수 있는 새로운 미디어입니다. 현재 이미 기술적인 기반은 충분한 상태이고 법제도를 정비하는 단계로 가고 있는 상황이죠.
 웹에서도 동영상 기술이 중요하게 된 지 오래입니다. 유튜브(YouTube)가 새로운 트렌드도 부상했고, 검색 포털들은 동영상 검색에 승부를 걸고 있으며, 동영상 플레이어에는 웹TV를 볼 수 있는 기능이 추가되고 있습니다. 그리고 (지금 와서 약간 뒷북치는 감이 없진 않지만) 웹에서 동영상 재생에 있어 빠질 수 없는 기술이 바로 스트리밍입니다.
웹에서도 동영상 기술이 중요하게 된 지 오래입니다. 유튜브(YouTube)가 새로운 트렌드도 부상했고, 검색 포털들은 동영상 검색에 승부를 걸고 있으며, 동영상 플레이어에는 웹TV를 볼 수 있는 기능이 추가되고 있습니다. 그리고 (지금 와서 약간 뒷북치는 감이 없진 않지만) 웹에서 동영상 재생에 있어 빠질 수 없는 기술이 바로 스트리밍입니다.
2400bps 모뎀을 사용하던 초창기 웹에는 이미지를 올리는 것만해도 큰 고역이었습니다. 페이지에 이미지를 올리는 것은 물론이고 페이지를 읽을 때에도 이미지는 큰 걸림돌이었죠. 그래서 초기 웹페이지는 텍스트 중심의 단조로운 구성을 취하게 됩니다. (미국이나 일부 유럽의 페이지들은 지금도 이미지 사용을 최소화하는 곳이 많죠) 물론 지금은 전용선에 의해 대규모의 패킷을 주고받을 수 있기 때문에 이미지 뿐만 아니라 플래시 까지 페이지에 덕지덕지 붙여도 뭐라고 할 사람이 많지는 않죠.(당연히 이런 페이지 구성은 정보 접근성에 비추어 볼 때 매우 좋지 않습니다)
하지만 이렇게 살림살이가 많이 나아졌어도 동영상은 부담스러운 존재입니다. 기껏해야 몇백KB 밖에 안되는 이미지에 비해, 동영상은 툭하면 몇백MB를 넘기기 일쑤입니다. 그래서 동영상은 일반적인 방식으로 열 수가 없는데, 보통 웹페이지를 브라우저로 열게 되면 페이지에 속해 있는 모든 파일들을 다운 받은 후에야 페이지를 제대로 볼 수 있기 때문에, 다운받는데 얼마나 많은 시간이 걸릴지 예측할 수 없는 동영상을 다 받기까지 기다릴 수는 없는 것이죠. 스트리밍 기술은 기본적으로 이러한 제약에 의해 출현하게 되었습니다.
 웹에서 동영상을 열게 되면 동영상 플레이어는 다음 두 가지 중에 하나를 하게 됩니다. "다운로드" 또는 "버퍼링"이죠. 만약 동영상이 스트리밍 방식으로 올라가 있지 않다면 "다운로드"하게 됩니다. 예전에는 당연히 다운로드가 다 끝나야지만 동영상을 볼 수 있었지만, 요즘엔 기술이 좋아져서 다운로드 중에도 받은 부분까지 동영상을 볼 수가 있게 되었죠. 즉, 다운로드 하면서 동영상을 틀어주는 것인데, 만약 동영상의 진행상황을 알려주는 프로그레시브바가 끝까지 차지 않았는데 동영상이 플레이되고, 영상이 나오는 중에 프로그레시브바가 끝까지 계속 올라가고 있다면, 이건 다운로드하면서 동영상을 재생해 주는 것으로 보면 됩니다. 물론 다운로드를 받는 것이기 때문에 플레이가 끝났을 때 사용자 컴퓨터 어딘가에 그 동영상 파일이 남아있게 됩니다. 만약 사용자가 같은 동영상을 다시 볼 때 이 파일이 캐시로 남아있다면 다운로드 없이 빠른 속도로 동영상을 감상할 수 있습니다.
웹에서 동영상을 열게 되면 동영상 플레이어는 다음 두 가지 중에 하나를 하게 됩니다. "다운로드" 또는 "버퍼링"이죠. 만약 동영상이 스트리밍 방식으로 올라가 있지 않다면 "다운로드"하게 됩니다. 예전에는 당연히 다운로드가 다 끝나야지만 동영상을 볼 수 있었지만, 요즘엔 기술이 좋아져서 다운로드 중에도 받은 부분까지 동영상을 볼 수가 있게 되었죠. 즉, 다운로드 하면서 동영상을 틀어주는 것인데, 만약 동영상의 진행상황을 알려주는 프로그레시브바가 끝까지 차지 않았는데 동영상이 플레이되고, 영상이 나오는 중에 프로그레시브바가 끝까지 계속 올라가고 있다면, 이건 다운로드하면서 동영상을 재생해 주는 것으로 보면 됩니다. 물론 다운로드를 받는 것이기 때문에 플레이가 끝났을 때 사용자 컴퓨터 어딘가에 그 동영상 파일이 남아있게 됩니다. 만약 사용자가 같은 동영상을 다시 볼 때 이 파일이 캐시로 남아있다면 다운로드 없이 빠른 속도로 동영상을 감상할 수 있습니다.
만약 동영상을 열었을 때 "버퍼링"을 한다면, 이 동영상은 스트리밍 방식으로 제공되는 것으로 보면 됩니다. 스트리밍은 실시간으로 동영상을 조금씩 흘려보내 주는 것으로서 플레이어에서는 그때그때마다 들어오는 데이터를 그대로 보여주는 셈입니다. 마치 TV에서 어디선가 날아오는 전파를 받아 바로 보여주듯이 말이죠. 하지만 인터넷 망의 상태에 따라 언제나 일정한 속도로 동영상 데이터가 들어오는 것이 아니기 때문에, 동영상이 끊기거나 지연되는 사태가 종종 발생합니다. 그래서 동영상 플레이어는 그런 지연을 방지하기 위해 얼마간의 데이터를 미리 받아놓고 상태가 좋지 않으면 미리 받아놓은 영상을 보여주어 끊기는 현상을 최대한 방지하려 합니다. 바로 이것을 "버퍼링"이라고 부르는 것이죠. (보통 망이 불안정해서 동영상이 자주 끊길 때 이 버퍼링이 많이 나오는데요, 버퍼링을 하기 때문에 나쁜 환경에서도 그나마 재생이 되는 것입니다) 스트리밍 방식으로 재생되는 동영상은 받은 데이터를 보여주고 그것으로 땡입니다. 따라서 다운로드 방식처럼 파일이 어딘가에 남거나 하지 않기 때문에, 만약 동영상을 다시 한 번 보고 싶다면 똑같이 버퍼링부터 하고 똑같은 데이터를 다시 받아 봐야 합니다. 별도의 복사본이 남지 않기 때문에 대부분의 유료 컨텐츠 등은 스트리밍 방식을 취하기도 합니다.
IPTV가 정식으로 서비스된다면 VOD 서비스와는 달리 TV처럼 실시간 방송을 보여주기 때문에 이러한 스트리밍 기술을 사용하게 될 것입니다. 많은 데이터를 빠른 시간에 보내고 받는 기술이 보다 중요해지겠죠. 기술의 진보는 누구나 보다 쉽게 방송을 할 수 있도록 도와줄 것 같습니다. 그러나 이와는 별개로 갖가지 법적, 제도적 장치들이 방송을 쉽게 하지 못하도록 막겠죠. 마치 FM 시대에 그랬던 것처럼, IPTV 시대에도 해적 방송이 다시 출현하지 않을지 모르겠습니다;;;
베타 테스트 시작한 지는 꽤 됐지만...
티스토리 분양 받았다.
(당연한 말이지만) 태터랑 거의 똑같은 기능과 인터페이스;;;
일단 열심히 사용하기로 혈서를 쓴 관계로-_-
티스토리에도 동시에 포스팅 해야 할 듯;;;
* 회사에서 청탁받아 쓴 글입니다;;;
Web 2.0이라는 단어가 전파된 것은 그야말로 순식간에 이루어진 일이었습니다. 마치 어느날 갑자기 모두가 웹2.0을 말하고 있었다는 느낌이었죠. 소수 집단에서 조심스럽게 나오기 시작했던 웹2.0은 개발자, 웹기획자 뿐만 아니라 관리자, 마케터 등 웹을 하는 사람이라면 반드시 알아야 할 것 같은 압박을 주는 단어로 성장했습니다.
웹2.0이라는 용어는 O'Reilly사와 MediaLive International사의 컨퍼런스를 위한 브레인스토밍 도중 최초로 도출되었다고 합니다. 이후 유명한 웹2.0의 meme map이 나왔으며 2004년 10월에 웹2.0 컨퍼런스가 개최되어 몇 가지 원칙 등이 정리되게 됩니다.
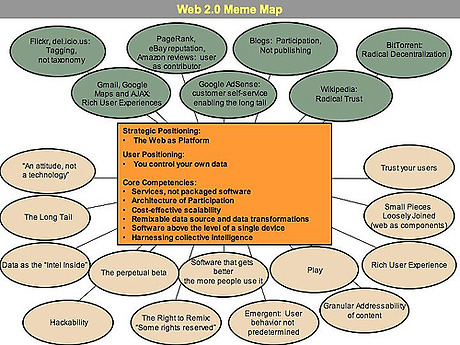
웹2.0의 meme map
이 meme map에 있는 말들이 곧 웹2.0에 대한 정의는 아닙니다. 사실 웹2.0이라는 단어는 그 안에 워낙 많은 개념들이 포함되어 있기 때문에 한 마디로 정의하기가 상당히 애매합니다. 단지 2.0이라는 숫자가 주는 새로움에 대한 인상이 워낙 강렬하기 때문에, 어렴풋이나마 이미지를 그려서 이야기 하는 경우가 많죠. 그래서 여기에선 그 의미를 정리하는 것보다는 몇 가지 대표적인 서비스들을 통해 웹2.0의 특징을 설명하도록 하겠습니다.
Computing with Google
국내에서 Google은 일반 사용자들에게 검색 시장을 정복한 업체 정도로 알려져 있지만, 사실 Google의 진정한 야망은 세계 정복에 있습니다. 지금까지 Google은 강력한 검색 서비스를 필두로 하여 뉴스 서비스, 맵 서비스, 데이터베이스 서비스, 데스크탑 툴바 등 컴퓨터로 할 수 있는 거의 모든 작업들에 개입하려 하고 있습니다. Google은 과거의 Netscape나 현재의 MS처럼 서버나 소프트웨어를 판매하지는 않지만, 이러한 서비스를 통해 데이터베이스를 수집하고 정보의 흐름을 매개함으로써 독립된 플랫폼을 구축하고 있죠(Services, not packaged software). Tim O'Reilly는 웹2.0의 전략적 포지셔닝으로서 "플랫폼으로서의 웹The Web as Platform"을 제시하고 있는데, Google은 이런 특징을 가장 잘 보여주는 서비스라고 할 수 있습니다.
Learning with Wikipedia
웹2.0을 설명하는데 있어 집단 지성Collective Intelligence은 빼놓을 수 없는 항목입니다. 사실 집단 지성은 인터넷이 시작되면서부터 지금까지 이어져 온 중요한 주제 중 하나입니다. 많은 사람들이 서로의 경험을 커뮤니케이션하며 가치를 만들어낸다는 이 개념은 1994년 프랑스의 사회학자/철학자인 피에르 레비Pierre Revy의 동명의 책에 등장했습니다. 인터넷의 발전에 따라 오픈소스 프로젝트, 블로그, 그리고 가장 급진적인 방식인 위키위키Wikiwiki까지 이어져 온 이 개념은 Wikipedia에서 가장 극명하게 드러나고 있죠.
Wikipedia는 위키의 편집 방식에 따라 누구나 쓸 수 있고 자신이 쓴 글은 물론이고 다른 이가 쓴 글까지도 수정, 삭제할 수 있습니다. 이는 위키를 사용하는 사람들에 대한 집단적인 이성을 극단적으로 신뢰하기 때문에 가능한 것이죠(Trust your users). 누군가에 의해 통제되는 것은 아니지만 사용자들은 스스로 데이터를 올리고 수정하면서 하나의 백과사전을 만들어가고 있습니다. 가끔 악의적인 사용자에 의해, 혹은 사용자의 실수에 의해 어떤 항목이 통째로 사라지는 경우가 발생하기도 하지만, 곧 다른 사용자에 의해 히스토리에서 복구되곤 하죠. 역시 많은 사용자들에 의해 데이터베이스가 쌓이고는 있지만 중복된 지식과 닫힌 구조의 한계를 지닌 지식인 서비스와 비교하여, 보다 신뢰할 수 있고 훨씬 많은 데이터를 제공할 수 있는 것도 Wikipedia이기 때문에 가능합니다.
- 논쟁의 여지가 있는 주제에 대해서는 편집에 제한을 가하기도 하고 토론도 전개하곤 합니다.
Tagging with delicious
delicious는 태그tag의 사용을 가장 잘 보여주는 서비스입니다. 태그는 말 그대로 뭔가에 붙이는 꼬리표입니다. 이 단순한 행위가 카테고리를 기본으로 하는 기존의 분류법taxonomy을 완전히 뒤집어 놓은 새로운 분류법folksonomy이 되고 있습니다.
북마크 서비스를 하는 delicious는 각 링크에 태그를 붙이도록 했습니다. 예를 들면 진보불로그에 진보넷, 블로그... 이런 식으로 말이죠. 저장된 북마크는 이러한 태그에 의해 분류해서 관리합니다. 그리고 이렇게 각 사용자들이 모은 북마크를 공유(소셜 북마크Social Bookmark)합니다. 어떤 사이트가 유용한 곳인지 다른 사람들이 저장해 놓은 북마크를 통해 쉽게 찾을 수 있습니다. 그리고 만약 "블로그"라는 태그를 진보불로그에 붙여 저장한 사람이 많아진다면 진보불로그의 순위도 점점 높아지게 됩니다. 태그를 붙이는 행위인 태깅tagging은 곧 가치있는 사이트를 찾는 일에 사람들을 참여하게 하는 방법이기도 한 것이죠(Architecture of Participation). 지금은 동영상, 사진, 포스트 등 웬만한 컨텐트를 생성할 때 태그를 다는 것은 하나의 추세가 되고 있습니다.
Mashing with Google Maps
앞에서 Google 서비스들에 대해 얘기했지만, 그 중 가장 웹2.0적인 서비스는 단연 Google Maps입니다. Ajax라는 비동기 처리 기술을 사용한 Rich Interface도 돋보이지만, 무엇보다도 다른 웹 어플리케이션과 쉽게 매쉬업mash-up 가능하다는 점이 가장 웹2.0답다고 할 수 있습니다(Remixable data source and data transformation). Tim O'Reilly의 글에서 소개되기도 한 하우징맵스닷컴의 경우를 보면 Google Maps의 데이터가 다른 데이터들과 어떻게 섞일 수 있는지 알 수 있습니다.
Google Maps의 데이터는 그 자체로도 물론 가치가 있겠지만, 사방으로 흘러나가 다른 데이터와 섞여 또 다른 가치를 만들어냅니다. 그 작업을 하는 것은 Google Maps가 아니라 그 사용자들이며, Google Maps는 데이터베이스를 소유하는 것이 아니라 매개하는 역할을 하는 것이죠. 이쯤되면 Google의 세계 정복 야망이 왠지 현실성 있어 보이는 것 같습니다.
웹2.0은 아직 진행중
이렇게 여러 서비스들을 늘어놓고 보면 웹2.0에 대해 어렴풋이 이해가 될 듯 할 것 같지만, 막상 웹2.0을 정의하려면 어떤 설명부터 해야 할지 난감하긴 여전합니다. 웹2.0은 아직까지도 차세대 웹의 모습으로서 각광을 받고 있긴 하지만, 한 편으로는 예전부터 있던 개념을 새삼스레 꺼낸다-한 마디로 뒷북이란 얘기죠-고 생각도 있고, 극단적으로는 단지 마케팅 용어일 뿐이라는 주장도 있습니다. 그러나 어떻게 보면 새로운 기술, 풍부해진 유저 인터페이스 등과 함께 그 동안 주류에서 밀려나 있었던 웹의 진정한 의미를 찾았다는 뜻으로 "2.0"이라는 숫자는 정당하다고 생각합니다.
아직 한국에서는 웹2.0 서비스라고 예를 들 만한 곳이 별로 없습니다. 한국에서의 인터넷 환경의 특수성이라는 것이 있기 때문에, 제대로 된 웹2.0 서비스가 탄생하기 위해서 좀 더 시간이 필요할지도 모르겠습니다. 처음에는 생소하기만 했던 RSS 서비스, 태깅 등이 일반화되고 있고 API 서비스 등이 신규 오픈되고 Long Tail의 중요성이 부각되어가는 것을 보면, 머지않아 한국에서도 신선한 웹2.0 서비스라고 부를 만한 것을 볼 수 있지 않을까요?

댓글 목록
관리 메뉴
본문
안녕하세요, 'renegade'님, 윙버스(http://wingbus.com)컨텐츠팀입니다.renegade님의 소중한 여행 자료가 저희 윙버스 사이트에 등록되어서 알려드리려구요.
어느 도시, 어느 스팟에 쓰였는지 아래의 링크를 클릭해 보시면 확인하실 수 있습니다.
http://www.wingbus.com/user/regi_info.wbs?037c7c0a0d44dde5f1ae00d772b2d6d0
다시 한번 다른 여행자들에게 도움이 될 수 있는 귀중한 자료를 공유해주신 점 깊이 감사드립니다.
부가 정보